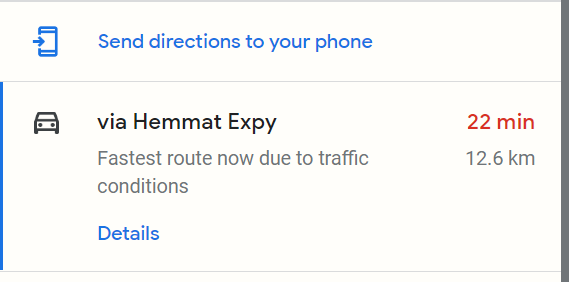
I am scraping travel times from Google Maps. The below code scrapes travel times between 1 million random points in Tehran, which works perfectly fine. I also use multiprocessing to get travel times simultaneously. The results are fully replicable, feel free to run the code in a terminal (but not in an interactive session like Spyder as the multiprocessing won't work). This is how what I am scraping looks like on google maps (in this case 22 min is the travel time):
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from multiprocessing import Process, Pipe, Pool, Value
import time
from multiprocessing.pool import ThreadPool
import threading
import gc
threadLocal = threading.local()
class Driver:
def __init__(self):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_experimental_option('excludeSwitches', ['enable-logging'])
self.driver = webdriver.Chrome(options=options)
def __del__(self):
self.driver.quit() # clean up driver when we are cleaned up
print('The driver has been "quitted".')
@classmethod
def create_driver(cls):
the_driver = getattr(threadLocal, 'the_driver', None)
if the_driver is None:
print('Creating new driver.')
the_driver = cls()
threadLocal.the_driver = the_driver
driver = the_driver.driver
the_driver = None
return driver
success = Value('i', 0)
error = Value('i', 0)
def f(x):
global success
global error
with success.get_lock():
success.value = 1
print("Number of errors", success.value)
with error.get_lock():
error.value = 1
print("counter.value:", error.value)
def scraper(url):
"""
This now scrapes a single URL.
"""
global success
global error
try:
driver = Driver.create_driver()
driver.get(url)
time.sleep(1)
trip_times = driver.find_element(By.XPATH, "//div[contains(@aria-labelledby,'section-directions-trip-title')]//span[@jstcache='198']")
print("got data from: ", url)
print(trip_times.text)
with success.get_lock():
success.value = 1
print("Number of sucessful scrapes: ", success.value)
except Exception as e:
# print(f"Error: {e}")
with error.get_lock():
error.value = 1
print("Number of errors", error.value)
import random
min_x = 35.617487
max_x = 35.783375
min_y = 51.132557
max_y = 51.492329
urls = []
for i in range(1000000):
x = random.uniform(min_x, max_x)
y = random.uniform(min_y, max_y)
url = f'https://www.google.com/maps/dir/{x},{y}/35.8069533,51.4261312/@35.700769,51.5571612,21z'
urls.append(url)
number_of_processes = min(2, len(urls))
start_time = time.time()
with ThreadPool(processes=number_of_processes) as pool:
# result_array = pool.map(scraper, urls)
result_array = pool.map(scraper, urls)
# Must ensure drivers are quitted before threads are destroyed:
del threadLocal
# This should ensure that the __del__ method is run on class Driver:
gc.collect()
pool.close()
pool.join()
print(result_array)
print( "total time: ", round((time.time()-start_time)/60, 1), "number of urls: ", len(URLs))
But after having it run for only 24 hours, it has already used around 80 GB of data! Is there a way to make this more efficient in terms of data usage?
I suspect this excessive data usage is because Selenium has to load each URL completely every time before it can access the HTML and get the target node. Can I change anything in my code to prevent that and still get the travel time?
*Please note that using the Google Maps API is not an option. Because the limit is too small for my application and the service is not provided in my country.
CodePudding user response:
You can use Page Load Strategy.
A Selenium WebDriver has 3 Page Load Strategy:
normal- Waits for all resources to download.eager- DOM access is ready, but other resources like images may still be loading.none- Does not block WebDriver at all.
options.page_load_strategy = "none" # ["normal", "eager", "none"]
It might help you (obviously it doesn't perform mirakle, but better than nothing).