I have 3 Data-frames of Following Shapes:
(34376, 13), (52389, 28), (16531, 14)
This is the First Dataframe which we have:
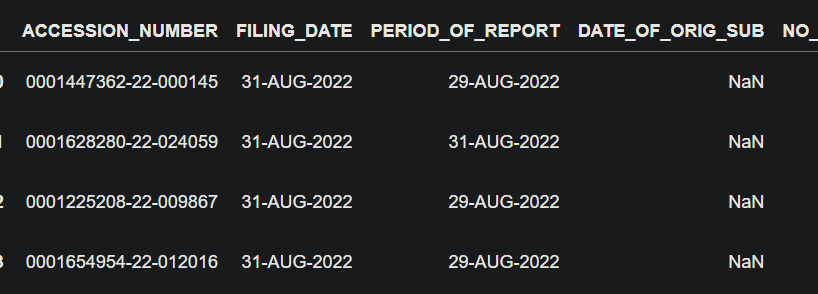
This is the Second Dataframe which we have:
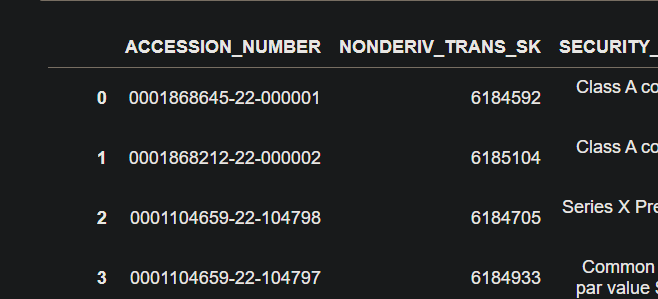
This the Third Dataframe which we have:
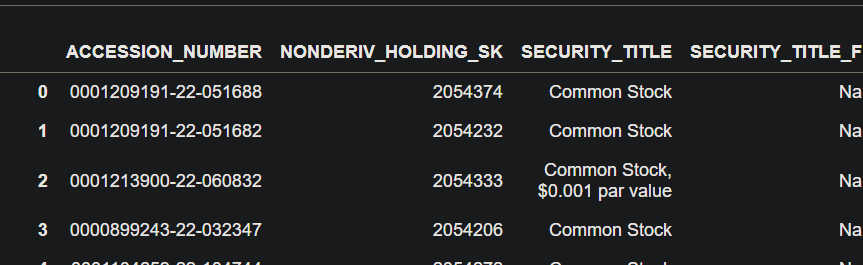
Now, as I have mentioned the shapes of all the Dataframes, the main task is we have to merge this on the Accession Number \
DF1-has the exact 34376 Accession which we want.
DF2- has around 28000 Accession which we want. This basically means that the remaining Accession of that table we don't want.
DF3- has around 9200 Accession which we want
How can we, merge all these 3 DF's on Accession Number, so that we get the extra columns of DF2,DF3 merged with DF1 on Accession Number. Also, we can see that DF2 has 52389 columns, so if there are same Accession Numbers repeated in DF2, we still want to merge it, but the rows of DF1 should be repeated while merged with the extra rows of DF2 and same with DF3. The Accession where no values are available in DF2/DF3 but present in DF1, the rows should become Null.
CodePudding user response:
To merge two data frames in Pandas, you can use the pd.merge() function. This function allows you to combine data from two data frames based on a common column or index.
Here is an example of how to use pd.merge() to merge two data frames df1 and df2 based on a common column called id:
import pandas as pd
df1 = pd.DataFrame({'id': [1, 2, 3], 'value': [4, 5, 6]}) df2 = pd.DataFrame({'id': [2, 3, 4], 'value': [7, 8, 9]})
df3 = pd.merge(df1, df2, on='id') print(df3)
To merge two data frames in Pandas, you can use the pd.merge() function. This function allows you to combine data from two data frames based on a common column or index.
Here is an example of how to use pd.merge() to merge two data frames df1 and df2 based on a common column called id:
Copy code import pandas as pd
df1 = pd.DataFrame({'id': [1, 2, 3], 'value': [4, 5, 6]}) df2 = pd.DataFrame({'id': [2, 3, 4], 'value': [7, 8, 9]})
df3 = pd.merge(df1, df2, on='id') print(df3)
This will merge the two data frames based on the values in the id column, and the resulting data frame will look like this:
id value_x value_y 0 2 5 7 1 3 6 8
The resulting data frame will have a row for each unique value of id that appears in either df1 or df2, and the columns from both data frames will be included, with suffixes _x and _y added to distinguish between the two.
You can also use the how parameter to specify the type of merge to perform (e.g. left, right, outer, inner).
CodePudding user response:
You can simply use the pandas merge function
pd.merge(pd.merge(df1,df2,on='ACCESSION_NUMBER'),df3,on='ACCESSION_NUMBER')
or
df1.merge(df2,on='ACCESSION_NUMBER').merge(df3,on='ACCESSION_NUMBER')
or
You could use the reduce class from functools library
reduce(lambda x,y: pd.merge(x,y, on='ACCESSION_NUMBER', how='outer'), [df1, df2, df3])