Problem Statement: Need to filldown a filtered dataframe.
I have a large dataframe. It is not shown here but I have included a dummy dataframe as an example below.
The only Status/State combinations I want are UP/GOOD and DOWN/BAD.
My dataset currently has undesired DOWN/GOOD combination and I'm trying to correct it to DOWN/BAD by filling down a filtered dataframe. Please advise on the code below, it is not working. There are couple of other solutions to this problem but I would like the filldown (.ffill) method.
Thanks!
Unfiltered dataset
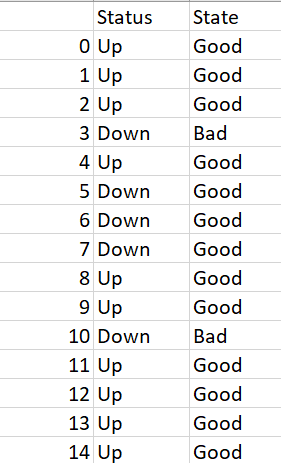
Filtered Dataset: Down status shown
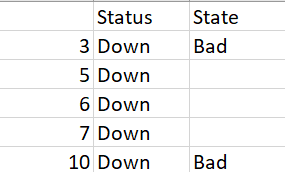
Desired Solution
Code:
"""This is a dummy dataframe"""
import pandas as pd
import numpy as np
dummydata=[["Up","Good"],["Up","Good"],["Up","Good"],["Down","Bad"],["Up","Good"],
["Down","Good"],["Down","Good"],["Down","Good"],["Up","Good"],["Up","Good"],
["Down","Bad"],["Up","Good"],["Up","Good"],["Up","Good"],["Up","Good"]]
df=pd.DataFrame(dummydata, columns=['Status','State'])
filt=df['Status']=="Down"
df2=df.loc[filt]
df2.loc[df2['State']=='Good','State']=""
df2.loc[df2.State=='','State']= np.nan
df2.loc[df2['State']=='','State']=df2['State'].ffill()
print(df,df2)
My current filldown method is not working. Code is provided. Any help will be appreciated
CodePudding user response:
There are a few issues with your code:
You are trying to fill down the values in df2, which is a separate dataframe that you created by filtering df. However, the changes you are making to df2 are not reflected in df. To fix this, you can either modify the values in df directly, or you can update df2 and then use the updated df2 to update df.
You are replacing the values in the State column with an empty string, and then filling down these empty strings. However, ffill only works with NaN values, so you will need to replace the empty strings with NaN instead.
Your code is not handling the case where the State column already has the correct value of "Bad". In this case, you don't want to overwrite the value with an empty string or NaN, but your current code will do that.
Here's an example of how you could modify your code to fix these issues:
filt = df['Status'] == "Down"
df.loc[filt, 'State'] = np.where(df['State'] == 'Good', np.nan, df['State'])
df['State'] = df['State'].ffill()
This code will update the values in the df dataframe directly, and will only change the State values that are "Good" to NaN, while leaving the other values unchanged. Then it will fill down the NaN values using ffill.
Hopefully this helps you out a bit.
CodePudding user response:
There is no need for slicing here.
The most simple would be to do:
df2['State'] = df2['State'].replace('Good', np.nan).ffill()
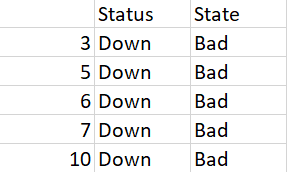
Output:
Status State
3 Down Bad
5 Down Bad
6 Down Bad
7 Down Bad
10 Down Bad
CodePudding user response:
use this :
df.loc[df['Status']=='Down','State']='Bad'
df[df['Status']=='Down']
Status State
3 Down Bad
5 Down Bad
6 Down Bad
7 Down Bad
10 Down Bad
CodePudding user response:
You can directly filter them using condition and assign them.
Code:
import pandas as pd
import numpy as np
dummydata=[["Up","Good"],["Up","Good"],["Up","Good"],["Down","Bad"],["Up","Good"],
["Down","Good"],["Down","Good"],["Down","Good"],["Up","Good"],["Up","Good"],
["Down","Bad"],["Up","Good"],["Up","Good"],["Up","Good"],["Up","Good"]]
df=pd.DataFrame(dummydata, columns=['Status','State'])
#Filter Status == Down and State == Good
df.loc[((df["Status"] == "Down") & (df["State"] =="Good")), "State"] = "Bad"