I'm relatively new to multithread programming. I wrote a program which is calculating the squares from 0 - 10000 and saving them into an array. The sequential program is running much faster than the parallel. In my parallel program I have divided the loop into 8 threads (my machine has 8 cores) but it is much slower! Anyone an idea why this is the case? I have added the screenshots of the execution times.
/*Here is the normal program:*/
#define ARRAYSIZE 10000
int main(void) {
int array[ARRAYSIZE];
int i;
for (i=0; i<ARRAYSIZE; i )
{
array[i]=i*i;
}
return 0;
}
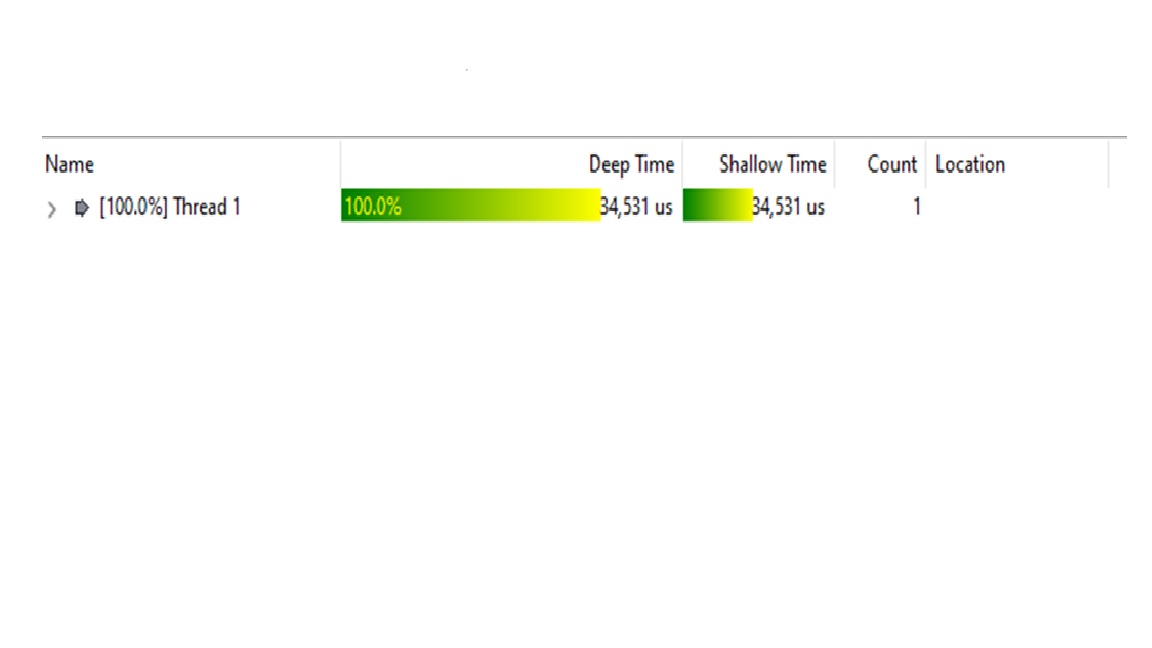
/*Here is the parallelized calculation. Used from http://ramcdougal.com/threads.html*/
#include <stdio.h>
#include <pthread.h>
#define ARRAYSIZE 10000
#define NUMTHREADS 8 /*Cause have 8 core on my machine*/
struct ThreadData {
int start;
int stop;
int* array;
};
void* squarer (struct ThreadData* td);
/* puts i^2 into array positions i=start to stop-1 */
void* squarer (struct ThreadData* td)
{
struct ThreadData* data = (struct ThreadData*) td;
int start=data->start;
int stop=data->stop;
int* array=data->array;
int i;
for(i= start; i<stop; i )
{
array[i]=i*i;
}
return NULL;
}
int main(void) {
int array[ARRAYSIZE];
pthread_t thread[NUMTHREADS];
struct ThreadData data[NUMTHREADS];
int i;
int tasksPerThread= (ARRAYSIZE NUMTHREADS - 1)/ NUMTHREADS;
/* Divide work for threads, prepare parameters */
/* This means in my example I divide the loop into 8 regions: 0 ..1250,1250 .. 2500 etc., 2500 .. 3750 */
for(i=0; i<NUMTHREADS;i )
{
data[i].start=i*tasksPerThread;
data[i].stop=(i 1)*tasksPerThread;
data[i].array=array;
data[NUMTHREADS-1].stop=ARRAYSIZE;
}
for(i=0; i<NUMTHREADS;i )
{
pthread_create(&thread[i], NULL, squarer, &data[i]);
}
for(i=0; i<NUMTHREADS;i )
{
pthread_join(thread[i], NULL);
}
return 0;
}
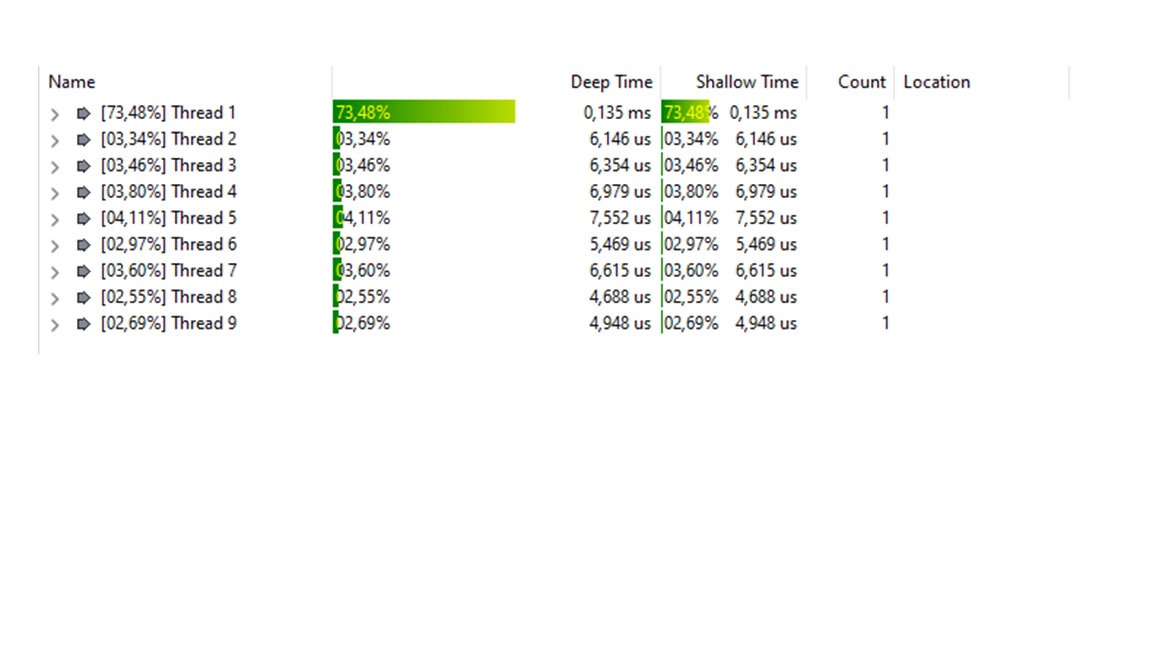
CodePudding user response:
You want to have a garden party. In preparation, you must move 8 chairs from the house into the garden. You call a moving company and ask them to send 8 movers. They arrive from across town and quickly complete the task, one chair each. The 8 movers drive back to the other end of the town. When they return, they call you and tell you that the task has been completed.
Question: Would the whole process have gone faster if you had moved the 8 chairs yourself?
Answer: Yes, the actual task (moving 8 chairs a short distance) is far too small to involve a moving company. The time spent on transport back and forth far exceeds the time spent on the task itself.
The example above is similar to what your code does.
Starting 8 threads is equivalent to driving from the other end of town to your house.
Stopping 8 threads is equivalent to returning back.
There is far too much wasted time compared to the size of the task to be solved.
Lesson: Only use multi-threading when the task is sufficiently big.
So for your test, you should increase ARRAYSIZE (a lot). Further, you have to add some code that prevents the compiler from doing optimizations that bypass the array assignments.
Try the code below (It's OPs code with a few changes).
Single thread
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define ARRAYSIZE 1000000000
unsigned array[ARRAYSIZE];
int main(void) {
unsigned i;
for (i=0; i<ARRAYSIZE; i )
{
array[i]=i*i;
}
srand(time(NULL));
return array[rand() % ARRAYSIZE] > 10000;
}
My result: 1.169 s
Multi thread
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define ARRAYSIZE 1000000000
unsigned array[ARRAYSIZE];
#define NUMTHREADS 8 /*Cause have 8 core on my machine*/
struct ThreadData {
unsigned start;
unsigned stop;
unsigned* array;
};
/* puts i^2 into array positions i=start to stop-1 */
void* squarer (void* td)
{
struct ThreadData* data = (struct ThreadData*) td;
unsigned start=data->start;
unsigned stop=data->stop;
unsigned* array=data->array;
unsigned i;
for(i= start; i<stop; i )
{
array[i]=i*i;
}
return NULL;
}
int main(void) {
pthread_t thread[NUMTHREADS];
struct ThreadData data[NUMTHREADS];
int i;
int tasksPerThread= (ARRAYSIZE NUMTHREADS - 1)/ NUMTHREADS;
/* Divide work for threads, prepare parameters */
/* This means in my example I divide the loop into 8 regions: 0 ..1250,1250 .. 2500 etc., 2500 .. 3750 */
for(i=0; i<NUMTHREADS;i )
{
data[i].start=i*tasksPerThread;
data[i].stop=(i 1)*tasksPerThread;
data[i].array=array;
data[NUMTHREADS-1].stop=ARRAYSIZE;
}
for(i=0; i<NUMTHREADS;i )
{
pthread_create(&thread[i], NULL, squarer, &data[i]);
}
for(i=0; i<NUMTHREADS;i )
{
pthread_join(thread[i], NULL);
}
srand(time(NULL));
return array[rand() % ARRAYSIZE] > 10000;
}
My result: 0.192 s