I have two dataframes, one that has an address column that's an entire string of words, human-entered data, and university addresses(df) and I want to extract city information from that. So I use another master city data(world_countries) to identify which of these cities are present in the string and use that in a new column.
Initially, I attempted this join with a contains() which gave me bad values as it is searching for even the characters and lookalikes like below
df = df.join(world_countries, df.address.contains(world_countries.city), how='left')
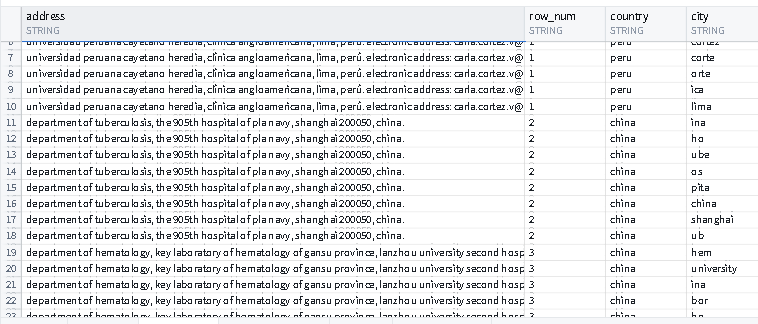
Gave me some results like this:
I understand what I need, I need to join whole words in strings, maybe something like a regexp string will help. but I don't have a said pattern to match on, I need the match to be on the entire column on a dataframe.
I can go the long way around, split the address into multiple columns and left join on each to find the match but that's just a lot and doesn't seem programmatically correct as well.
Please suggest a better way to do this, esp by joining on regexp on the entire column. Here is the code.
def pubmed2(pubmed_clean, worldcities):
df = pubmed_clean.selectExpr("AffiliationInfo as address").filter((F.col('address').isNotNull())).distinct()
w = Window().orderBy(lit('A'))
df = df.withColumn("row_num", row_number().over(w))
df= df.filter(F.col("row_num")<=100)
df = df.select([F.lower(col(c)).alias(c) for c in df.columns])
world_cities=worldcities.select([F.lower(col(c)).alias(c) for c in worldcities.columns])
df = udf(df, world_cities)
final = df.dropDuplicates()
return final
def udf(df,world_cities):
world_countries = (world_cities.selectExpr("country").distinct())#.withColumnRenamed(entity,"entity"))
df = (df.join(world_countries, df.address.contains(world_countries.country), how='left'))
world_countries = (world_cities.selectExpr("city").distinct())
df = df.join(world_countries,df.address.contains(world_countries.city), how='left')
return df
Sample data:
Centre for Primary Health Care, University of Basel, Kantonsspital Baselland, Rheinstrasse 26, 4410, Liestal, Switzerland.
Department of Family Medicine, Healthcare System Gangnam Center, Seoul National University Hospital, Seoul, 06236, Republic of Korea.
Department of Medical-Surgical Nursing, School of Nursing & Midwifery, Shahid Beheshti University of Medical Sciences, Tehran, Iran.
Department of Nursing, Federal University of the Valleys of Jequitinhonha and Mucuri, Diamantina, Minas Gerais, Brazil. Laboratory of Bioengineering, Federal University of Minas Gerais, Belo Horizonte,Minas Gerais, Brazil.
Sensory Science Centre, Division of Food, Nutrition and Dietetics, School of Biosciences, The University of Nottingham, Sutton Bonington Campus, Leicestershire, LE12 5RD, UK.
University of Michigan Medical School, Ann Arbor, MI, USA.
CodePudding user response:
This works
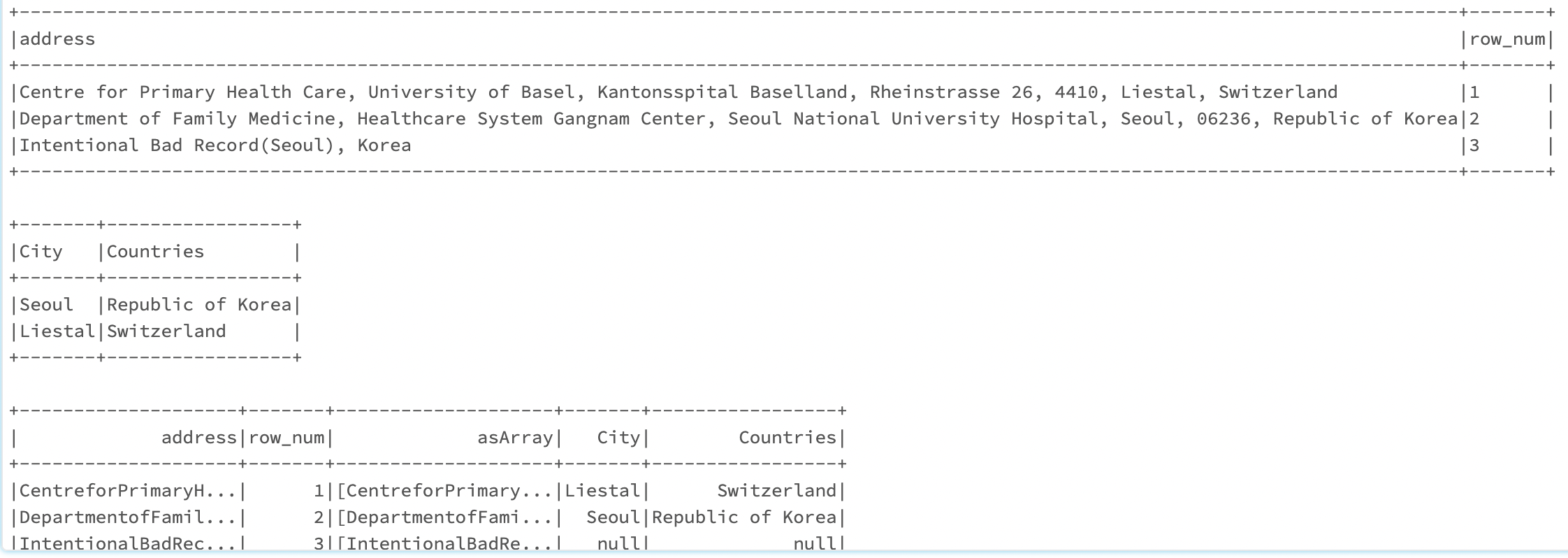
df = spark.createDataFrame([["Centre for Primary Health Care, University of Basel, Kantonsspital Baselland, Rheinstrasse 26, 4410, Liestal, Switzerland","1"],\
["Department of Family Medicine, Healthcare System Gangnam Center, Seoul National University Hospital, Seoul, 06236, Republic of Korea","2"],\
["Intentional Bad Record(Seoul), Korea", "3"]])\
.toDF("address", "row_num");
world_countries = spark.createDataFrame([["Seoul","Republic of Korea"],["Liestal","Switzerland"]]).toDF("City", "Countries");
df=df.withColumn("address",F.regexp_replace(F.col("address"), " ", "")).withColumn("asArray", F.split("address", ","));
df.join(world_countries, F.array_contains(df["asArray"], world_countries["City"]), how='left').show()
As you can see the record with row_num=3 contains the word "Seoul" within the first string, but won't be matched with Seoul as "a city" during the Join.
Input/Output: