this might seem like a trivia question: I have a list of datapoints that have been recorded every 5 minutes with an overlap of 2.5 minutes (2 and a half minutes). I also have the timestamp of the start of the recording and another timestamp from where I need to start counting the time (e.g. the chronometer start):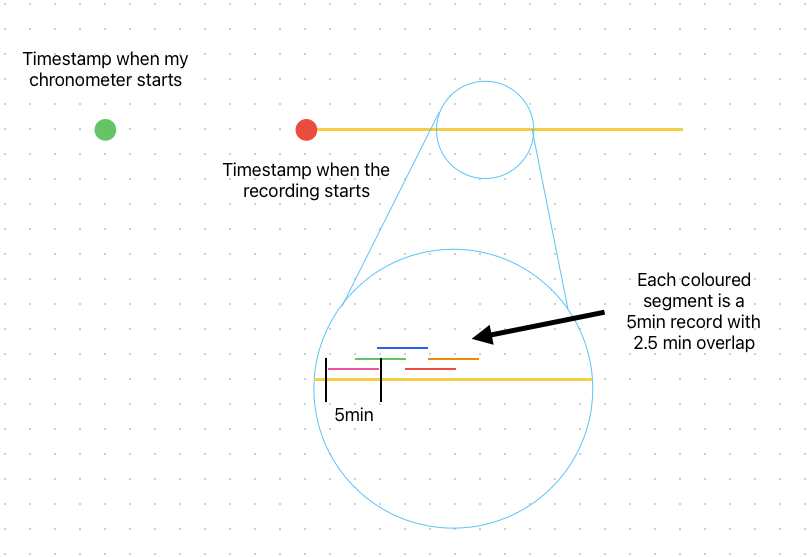
I need to calculate how many hours have past from the start of the chronometer to the end of the recordings and make a dataframe where in one column I have the recordings and in another column the hour from the start of the chronometer to which that recording belongs: e.g.
| recording | hours from chronometer start |
|---|---|
| 0.262 | 0 |
| 0.243 | 0 |
| 0.263 | 0 |
| 0.342 | 1 |
| 0.765 | 1 |
| 0.111 | 1 |
| ... | ... |
This is how I'm doing it in python:
import numpy as np
import pandas as pd
from math import floor
recordings = list(np.random.rand(1000)) # an example of recording
chronometer_start = 1670000000 #timestamp
start_recording = 1673280570 #timestamp
gap_in_seconds = start_recording - chronometer_start
# given that the recordings are of 5 minutes each but with 2.5 minutes overlap,
# I can calculate how many Null values to add at the beginning of the recording to
# fill the gap from the chronometer start:
gap_in_n_records = round(gap_in_seconds / 60 / 2.5)
# fill the gap with null values
recordings = [np.nan for _ in range(gap_in_n_records)] recordings
minutes = [5] # the first recording has no overlap
for _ in range(len(recordings)-1):
minutes = [minutes[-1] 2.5]
hours = pd.Series(minutes).apply(lambda x: floor(x/60))
df = pd.DataFrame({
'recording' : recordings,
'hour' : hours
})
But I'm worried I'm making some mistakes because then my data don't align with my results. Is there a better way of doing this?
CodePudding user response:
Firstly, to summarize and see if I understood you correctly. You have the chronometer that started at some point (could be days/weeks ago) and you have your datapoints that all take five minutes. You're looking for the hour (after the chronograph started) in which the datapoint ended.
For the first 5 records that would be:
| record index | minutes after recording start |
|---|---|
| 1 | 5 |
| 2 | 7.5 |
| 3 | 10 |
| 4 | 12.5 |
| 5 | 15 |
So we can summarize this into the formula:
time passed since recording start in minutes for datapoint n: 5 (n-1) * 2.5
We can use this formula and the index of the DataFrame to calculate the time that passed since the recording start and then add the time that passed between recording start and chronograph start:
import numpy as np
import pandas as pd
df = pd.DataFrame({"recordings": np.random.rand(1000)})
chronometer_start = 1670000000 # timestamp
start_recording = 1673280570 # timestamp
gap_in_seconds = start_recording - chronometer_start
# since the index of a pandas DataFrame starts at 0, we can make use of that (idx=n-1)
df["seconds_passed_since_chronometer_start"] = 5 df.index * (2.5 * 60) (gap_in_seconds)
# assuming that the first hour after the chronometer starts is hour 0, the column would be:
df["hours"] = df["seconds_passed_since_chronometer_start"].apply(lambda x: int(x) // 3600)
final_df = df[["recordings", "hours"]]
CodePudding user response:
Tristan, I like your way of thinking. Just for completeness, this is what ChatGPT suggested:
import numpy as np
import pandas as pd
import datetime
recordings = list(np.random.rand(1000)) # example of recording
# given that the recordings are of 5 minutes each but with 2.5 minutes overlap,
# we can calculate the time interval between each recording in seconds
time_interval = 5 * 60 - 2.5 * 60
# create a list of timestamps for each recording
timestamps = [start_recording i * time_interval for i in range(len(recordings))]
# convert the timestamps to datetime objects
datetimes = [datetime.datetime.fromtimestamp(t) for t in timestamps]
# calculate the number of hours that have passed from the start of the chronometer to each recording
hours_from_chronometer_start = [(d - datetime.datetime.fromtimestamp(chronometer_start)).total_seconds() / 3600 for d in datetimes]
# create the dataframe
df = pd.DataFrame({
'recording': recordings,
'hours from chronometer start': hours_from_chronometer_start
})
All Solutions bring to the same results. This is somewhat reassuring, it means the issue in my particular situation is somewhere else and not in the time-series.