I have a dataframe, wherein the column 'team' needs to be encoded.
These are my codes:
#Load the required libraries
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
#Create dictionary
data = {'team': ['A', 'A', 'B', 'B', 'C'],
'Income': [5849, 4583, 3000, 2583, 6000],
'Coapplicant Income': [0, 1508, 0, 2358, 0],
'LoanAmount': [123, 128, 66, 120, 141]}
#Convert dictionary to dataframe
df = pd.DataFrame(data)
print("\n df",df)
# Initiate label encoder
le = LabelEncoder()
# return encoded label
label = le.fit_transform(df['team'])
# printing label
print("\n label =",label )
# removing the column 'team' from df
df.drop("team", axis=1, inplace=True)
# Appending the array to our dataFrame
df["team"] = label
# printing Dataframe
print("\n df",df)
I am getting the below result after encoding:
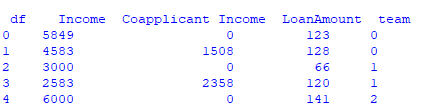
However, I wish to ensure following two things:
- Encoding starts with 1 and not 0
- The location of column 'team' should remain the same as original i.e. I wish to have following result:

Can somebody please help me out how to do this ?
CodePudding user response:
Do not drop the column and increment the label on assignment:
le = LabelEncoder()
# return encoded label
label = le.fit_transform(df['team'])
# Replacing the column
df["team"] = label 1
Output:
| df | team | Income | Coapplicant Income | LoanAmount |
|---|---|---|---|---|
| 0 | 1 | 5849 | 0 | 123 |
| 1 | 1 | 4583 | 1508 | 128 |
| 2 | 2 | 3000 | 0 | 66 |
| 3 | 2 | 2583 | 2358 | 120 |
| 4 | 3 | 6000 | 0 | 141 |