I am trying to extract text between a word and a symbol.
Here is the input table.
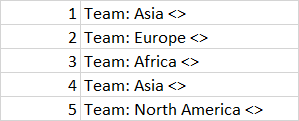
And my expected output is like this.
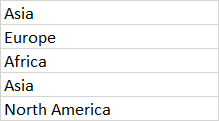
I do not want to have the word 'Team:' and '<>' in the output.
I tried something like this but it keeps the 'Team:' and '<>' in the output: data[new col]=data['Team'].str.extract(r'(Team:\s[a-zA-Z\s] <>)
Thank you.
CodePudding user response:
Use regex captured group for str.extract method:
df['Team'].str.extract(r'^Team: ([^<>] )')
[^<>]- matches any character except<and>chars
CodePudding user response:
You can do this with a regular expression as this would account for countries with spaces and any N length.
import re
row_string = "Team: United States <>"
country_name = re.search(r'Team: (.*) <>', row_string).group(1)