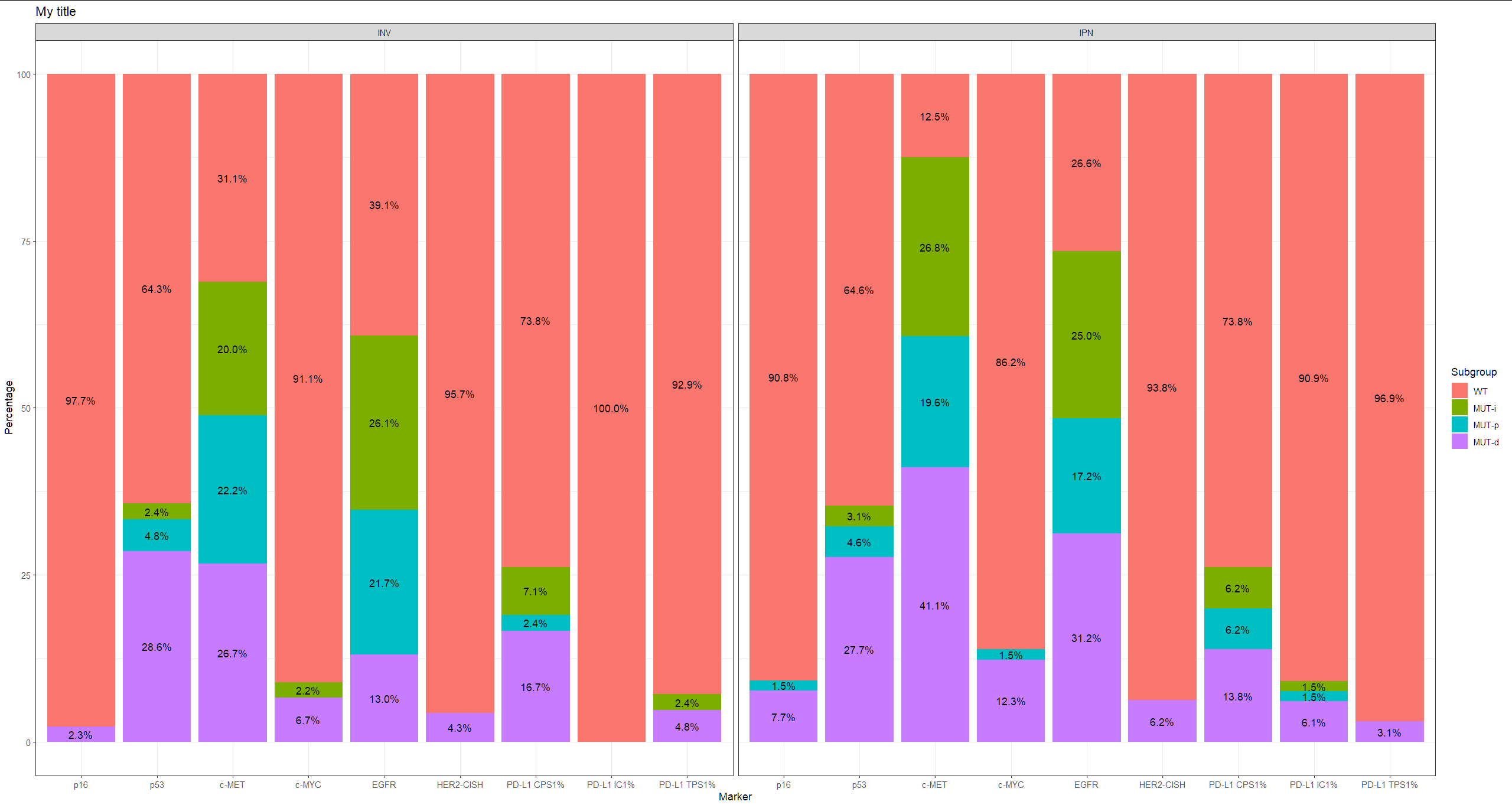
I am trying to plot a stacked barplot using the following df. My goal is to show the differential distribution of the "Marker"s in two different "Group"s (IPN, INV), so that the sum of all 4 subgroups (WT, MUT-i, MUT-p, MUT-d) equals a 100%.
What is the best approach to do this?
structure(list(Marker = c("p16", "p16", "p16", "p16", "p16",
"p16", "p16", "p16", "p53", "p53", "p53", "p53", "p53", "p53",
"p53", "p53", "c-MET", "c-MET", "c-MET", "c-MET", "c-MET", "c-MET",
"c-MET", "c-MET", "c-MYC", "c-MYC", "c-MYC", "c-MYC", "c-MYC",
"c-MYC", "c-MYC", "c-MYC", "EGFR", "EGFR", "EGFR", "EGFR", "EGFR",
"EGFR", "EGFR", "EGFR", "HER2-CISH", "HER2-CISH", "HER2-CISH",
"HER2-CISH", "HER2-CISH", "HER2-CISH", "HER2-CISH", "HER2-CISH",
"PD-L1 IC1%", "PD-L1 IC1%", "PD-L1 IC1%", "PD-L1 IC1%", "PD-L1 IC1%",
"PD-L1 IC1%", "PD-L1 IC1%", "PD-L1 IC1%", "PD-L1 TPS1%", "PD-L1 TPS1%",
"PD-L1 TPS1%", "PD-L1 TPS1%", "PD-L1 TPS1%", "PD-L1 TPS1%", "PD-L1 TPS1%",
"PD-L1 TPS1%", "PD-L1 CPS1%", "PD-L1 CPS1%", "PD-L1 CPS1%", "PD-L1 CPS1%",
"PD-L1 CPS1%", "PD-L1 CPS1%", "PD-L1 CPS1%", "PD-L1 CPS1%"),
Group = c("IPN", "IPN", "IPN", "IPN", "INV", "INV", "INV",
"INV", "IPN", "IPN", "IPN", "IPN", "INV", "INV", "INV", "INV",
"IPN", "IPN", "IPN", "IPN", "INV", "INV", "INV", "INV", "IPN",
"IPN", "IPN", "IPN", "INV", "INV", "INV", "INV", "IPN", "IPN",
"IPN", "IPN", "INV", "INV", "INV", "INV", "IPN", "IPN", "IPN",
"IPN", "INV", "INV", "INV", "INV", "IPN", "IPN", "IPN", "IPN",
"INV", "INV", "INV", "INV", "IPN", "IPN", "IPN", "IPN", "INV",
"INV", "INV", "INV", "IPN", "IPN", "IPN", "IPN", "INV", "INV",
"INV", "INV"), Subgroup = c("WT", "MUT-i", "MUT-p", "MUT-d",
"WT", "MUT-i", "MUT-p", "MUT-d", "WT", "MUT-i", "MUT-p",
"MUT-d", "WT", "MUT-i", "MUT-p", "MUT-d", "WT", "MUT-i",
"MUT-p", "MUT-d", "WT", "MUT-i", "MUT-p", "MUT-d", "WT",
"MUT-i", "MUT-p", "MUT-d", "WT", "MUT-i", "MUT-p", "MUT-d",
"WT", "MUT-i", "MUT-p", "MUT-d", "WT", "MUT-i", "MUT-p",
"MUT-d", "WT", "MUT-i", "MUT-p", "MUT-d", "WT", "MUT-i",
"MUT-p", "MUT-d", "WT", "MUT-i", "MUT-p", "MUT-d", "WT",
"MUT-i", "MUT-p", "MUT-d", "WT", "MUT-i", "MUT-p", "MUT-d",
"WT", "MUT-i", "MUT-p", "MUT-d", "WT", "MUT-i", "MUT-p",
"MUT-d", "WT", "MUT-i", "MUT-p", "MUT-d"), `Number of Cases` = c(59,
0, 1, 5, 42, 0, 0, 1, 42, 2, 3, 18, 27, 1, 2, 12, 7, 15,
11, 23, 14, 9, 10, 12, 56, 0, 1, 8, 41, 1, 0, 3, 17, 16,
11, 20, 18, 12, 10, 6, 60, 0, 0, 4, 44, 0, 0, 2, 60, 1, 1,
4, 42, 0, 0, 0, 63, 0, 0, 2, 39, 1, 0, 2, 48, 4, 4, 9, 31,
3, 1, 7)), class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA,
-72L))type here
Objective, or something similar to it... Whichever you think is a good representation of the data
Thanks a lot!
CodePudding user response:
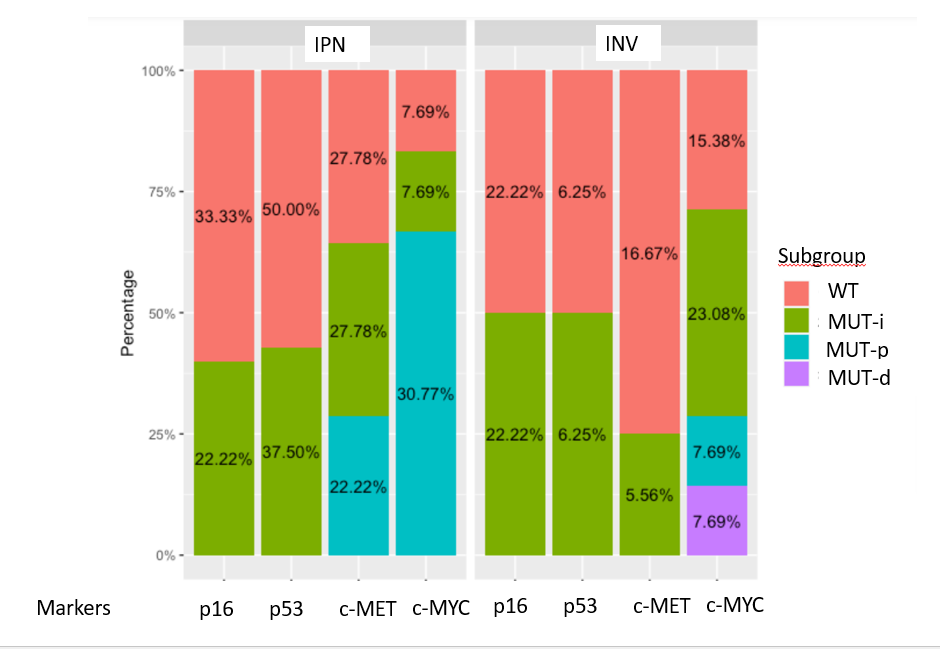
Update: request removing 0%: removed first solution:
One way to remove the 0% is to subset the data for labeling in ggtext.
library(tidyverse)
df1 <- df %>%
mutate(Marker = fct_relevel(Marker, c("p16", "p53", "c-MET", "c-MYC")),
Subgroup = fct_relevel(Subgroup, c("WT", "MUT-i", "MUT-p", "MUT-d"))) %>%
group_by(Group, Marker, Subgroup) %>%
summarise(sum=sum(`Number of Cases`)) %>%
# group_by(Subgroup) %>% #depends on what percent you want
mutate(pct= prop.table(sum) * 100)
ggplot(df1, aes(Marker, pct, fill=Subgroup))
geom_col(position = position_stack())
ylab("Percentage")
geom_text(data = df1 %>% filter(pct != 0),
aes(label=paste0(sprintf("%1.1f", pct),"%")),
position=position_stack(vjust=0.5))
facet_wrap(. ~ Group)
ggtitle("My title")
theme_bw()