I have a SQL Server table with around 10 columns containing various identifiers, both alphanumeric and numeric. I am writing a procedure which will allow a substring match to be performed across an arbitrary subset of those columns. For example, "the value in column B contains substring bSub AND the value in column D contains substring dSub AND the value in column G contains substring gSub".
The following works, but is blisteringly slow:
SELECT * FROM Table T
WHERE
(@aSub IS NULL OR T.A LIKE CONCAT('%', @aSub, '%')) AND
(@bSub IS NULL OR T.B LIKE CONCAT('%', @bSub, '%')) AND
...
(@jSub IS NULL OR T.J LIKE CONCAT('%', @jSub, '%'))
Is there another way to structure this query which would be more performant? Or any techniques to speed things up? I believe that indexes won't help due to the substring match LIKE('%...).
CodePudding user response:
In general, i'd say that string matching like this is always relatively slow. With that being said, there are couple of things you could try:
- Change LIKE to CHARINDEX. Since you don't actually match patterns, i suspect charindex is a bit more performant
- Instead of checking OR @a IS NULL etc, build query dynamically from parameters that are actually not NULL. Something like:
declare @sql = 'select .... WHERE 1 = 1'
if @a is not null
set @sql = @sql ' and CHARINDEX(@a, a) > 0'
if @b is not null
set @sql = @sql ' and CHARINDEX(@b, b) > 0'
...
exec SP_EXECUTESQL @sql N@a nvarchar(100)', @a = @a, @b = @b...
This would only check relevant columns.
- Create specific indexes for all or "most" searched for columns with the other needed columns as include. This might or might not help, but if you're lucky you can avoid full clustered index scan which is a lot more data to travel through than specific columns. This step is a bit tricky and might not help if SQL Server decides that it rather scans the clustered index anyway.
CodePudding user response:
I believe that indexes won't help due to the substring match LIKE('%...).
Yep, sadly this is true and there's no easy way around this. You could do something advanced like 
Next compare the actual number of rows each query processes:
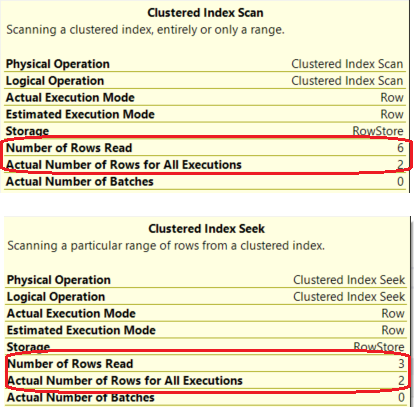
Leveraging the index on the computed column we are able to process 1/2 the rows (based on my sample data, I don't know what the real stuff looks like.)