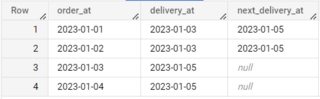
| order_at | delivery_at |
|---|---|
| 2023-01-01 | 2023-01-03 |
| 2023-01-02 | 2023-01-03 |
| 2023-01-03 | 2023-01-05 |
| 2023-01-04 | 2023-01-05 |
I want a new field, next_delivery_at, which is the first delivery_at in subsequents rows for each delivery_at, that is not the same value as delivery_at so the final table would be:
| order_at | delivery_at | next_delivery_at |
|---|---|---|
| 2023-01-01 | 2023-01-03 | 2023-01-05 |
| 2023-01-02 | 2023-01-03 | 2023-01-05 |
| 2023-01-03 | 2023-01-05 | null |
| 2023-01-04 | 2023-01-05 | null |
For this specific case, I could do something like:
CASE
WHEN (LEAD(delivery_at) OVER (PARTITION BY NULL ORDER BY delivery_at DESC) = delivery_at)
THEN (LEAD(delivery_at, 2) OVER (PARTITION BY NULL ORDER BY delivery_at DESC))
ELSE LEAD(delivery_at) OVER (PARTITION BY NULL ORDER BY delivery_at DESC)
END AS next_delivery_at
But if there are more than two rows in a row with the same delivery_at, the output will be wrong, so I am looking for a generic way of getting the first value in subsequents rows for delivery_at that is distinct for each delivery_at value.
CodePudding user response:
You can use a self join to match successive deliveries, then get the minimum next delivery.
SELECT t1.order_at, t1.delivery_at, MIN(t2.delivery_at) AS next_delivery_at
FROM tab t1
LEFT JOIN tab t2
ON t1.delivery_at < t2.delivery_at
GROUP BY t1.order_at, t1.delivery_at
CodePudding user response:
You might consider below using a logical window frame