I have this csv file favsites.csv:
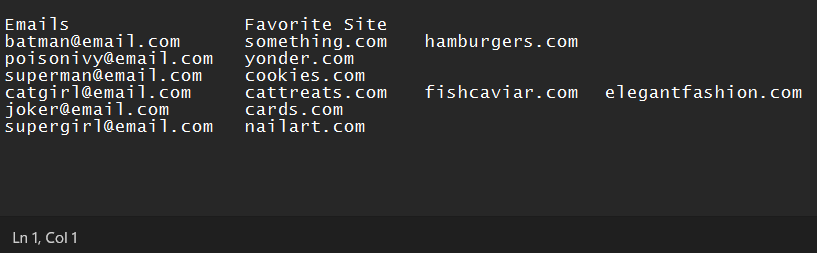
Emails Favorite Site
[email protected] something.com
[email protected] hamburgers.com
[email protected] yonder.com
[email protected] cookies.com
[email protected] cattreats.com
[email protected] fishcaviar.com
[email protected] elegantfashion.com
[email protected] cards.com
[email protected] nailart.com
I want to group the duplicates, then merge the columns, and then send to a csv.
So once grouped and merged it should look like this:
Emails Favorite Site
[email protected] something.com
hamburgers.com
[email protected] yonder.com
[email protected] cookies.com
[email protected] cattreats.com
fishcaviar.com
elegantfashion.com
[email protected] cards.com
[email protected] nailart.com
How would I send this to a csv file and have it look like this? But something.com and hamburgers.com are in one cell for batman; and cattreats.com, fishcaviar.com, and elegantfashion.com are in one cell for catgirl. OR, have them in the same row but different columns like this.
Emails Favorite Site
[email protected] something.com hamburgers.com
[email protected] yonder.com
[email protected] cookies.com
[email protected] cattreats.com fishcaviar.com elegantfashion.com
[email protected] cards.com
[email protected] nailart.com
Here is my code so far:
import pandas as pd
Dir='favsites.csv'
sendcsv='mergednames.csv'
df = pd.read_csv(Dir)
df = pd.DataFrame(df)
df_sort = df.sort_values('Emails')
grouped = df_sort.groupby(['Emails', 'Favorite Site']).agg('sum')
When I print grouped it shows:
Empty DataFrame
Columns: []
Index: [([email protected], hamburgers.com), ([email protected], something.com), ([email protected], cattreats.com), ([email protected], elegantfashion.com), ([email protected], fishcaviar.com), ([email protected], cards.com), ([email protected], yonder.com), ([email protected], nailart.com), ([email protected], cookies.com)]
CodePudding user response:
You can replace duplicated values with empty strings:
emails = ['[email protected]', '[email protected]','[email protected]', '[email protected]']
favs =['something.com', 'hamburgers.com', 'yonder.com', 'cookies.com' ]
df = pd.DataFrame({'Emails': emails, 'Favorite Site': favs})
df_sorted = df.sort_values('Emails')
df_sorted.loc[df['Emails'].duplicated(), 'Emails'] = ''
Output:
| Emails | Favorite Site |
|---|---|
| [email protected] | something.com |
| cookies.com | |
| [email protected] | hamburgers.com |
| [email protected] | yonder.com |
CodePudding user response:
IIUC, you can use 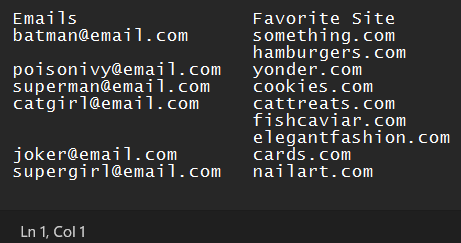
For the second format, you can use