I used pandas to clean a csv:
import pandas as pd
import numpy as np
df = pd.read_csv(r'C:\Users\Leo90\Downloads\data-export.csv',encoding='utf-8', header=None, sep='\n')
df = df[0].str.split(',', expand=True)
df=df.iloc[:,[0,1,2,3,4,5,6,7]]
df=df.replace(to_replace='None',value=np.nan).dropna()
df=df.reset_index(drop=True)
columnNames = df.iloc[0]
df = df[1:]
df.columns = columnNames
df.groupby('path').head()
The processed data like the screenshot below
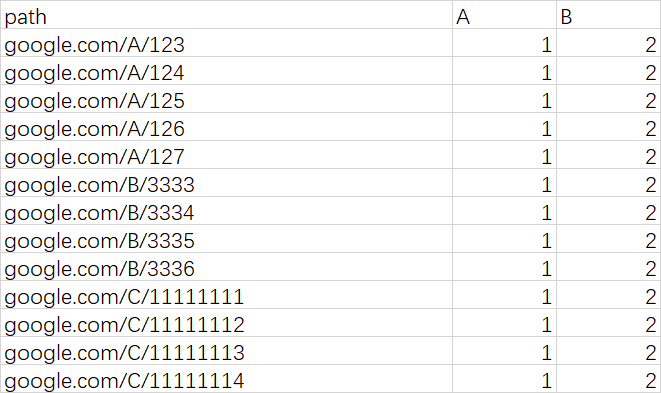
I want to use python to make this dataframe look like this

I know I could use str.contain to match these strings but it can only return bool, so I can't sum the A&B columns. Are there are any solutions for this problem?
I tried str.contain to match these strings but I can't sum A&B.
CodePudding user response:
Use groupby.sum based on the first 12 chars of the path column:
start = df['path'].str[:12] # first 12 chars of `path`
out = df.groupby(start).sum()
# A B
# path
# google.com/A 5 10
# google.com/B 4 8
# google.com/C 4 8
Or based on a str.extract regex that captures up to the 2nd slash:
start = df['path'].str.extract(r'^(.*/.*)/')[0] # up to the 2nd slash of `path`
out = df.groupby(start).sum()
# A B
# path
# google.com/A 5 10
# google.com/B 4 8
# google.com/C 4 8
CodePudding user response:
Group by the path whilst disregarding the final subpath and aggregate (sum) the other columns.
df['path'] = df["path"].apply(lambda x: "/".join(x.split("/")[:-1]))
df.groupby("path").sum()