How do you filter a pandas dataframe by row?
Seems like there's so many answers for filtering by column but none by row.
I have a simple df.describe() and would like to keep all columns that have a std of greater than 1000.
Current code is: df.describe().sort_values(by = 'std', axis = 1).loc['std'] > 1000 but does not work as intended.
Here is just some datapoints in my dataset, obviously there is more than 3 datapoints which is why i would need this function:
{'SalePrice': {'count': 1168.0,
'mean': 180382.8998287671,
'std': 78838.24838038624,
'min': 35311.0,
'25%': 129900.0,
'50%': 162950.0,
'75%': 214000.0,
'max': 755000.0},
'LotArea': {'count': 1168.0,
'mean': 10604.377568493152,
'std': 10603.205552654954,
'min': 1300.0,
'25%': 7598.25,
'50%': 9549.5,
'75%': 11628.5,
'max': 215245.0},
'MiscVal': {'count': 1168.0,
'mean': 47.08390410958904,
'std': 544.0945591249799,
'min': 0.0,
'25%': 0.0,
'50%': 0.0,
'75%': 0.0,
'max': 15500.0},
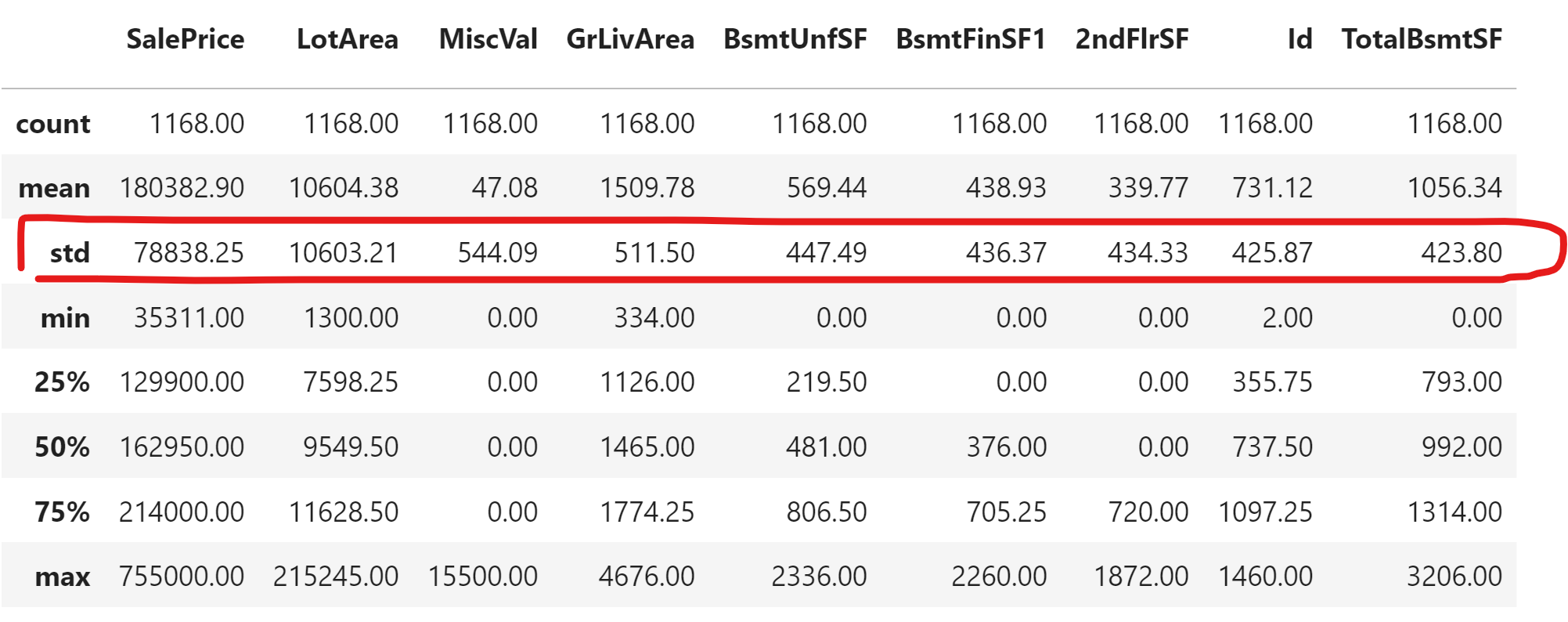
Added screen shot so you can see. Filter columns based on this row:
CodePudding user response:
For fun, you can make a double T (which is of course a waste of computations) :
out = df.T.loc[lambda x_: x_["std"].gt(1000)].T
And in a Pandorable way, as per @Scott Boston use boolean indexing and slice the columns :
out = df.loc[:, df.loc["std"].gt(1000)]
Output :
print(out)
SalePrice LotArea
count 1168.000000 1168.000000
mean 180382.899829 10604.377568
std 78838.248380 10603.205553 # <- both columns are greater than 1000
min 35311.000000 1300.000000
25% 129900.000000 7598.250000
50% 162950.000000 9549.500000
75% 214000.000000 11628.500000
max 755000.000000 215245.000000