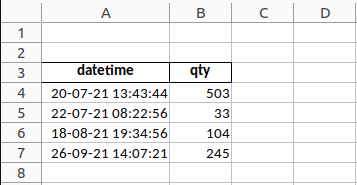
I have the below dataframe
Pandas Dataframe to Excel - Custom Date time format not applying
I have the below dataframe
df.head()
| datetime | qty | |
|---|---|---|
| 0 | 2021-07-20 13:43:44.915200 | 503 |
| 1 | 2021-07-22 08:22:56.037200 | 33 |
| 2 | 2021-08-18 19:34:56.142200 | 104 |
| 4 | 2021-09-26 14:07:21.628300 | 245 |
df.dtypes
datetime datetime64[ns]
qty float64
The issue I have is trying to get the format of the date-time column converted to dd-mm-yy hh:mm:ss when exporting to excel.
I've tried changing the format of the dataframe column but that results in changing the datatype from datatime64[ns] to object (i.e. string), with the result that it is no longer a formatted number in Excel. I want to keep the dataframe column as datetime64[ns] and hoping to find a solution that will format date time column in Excel as dd-mm-yy hh:mm:ss, keeping it as a formatted number.
I'm currently using the below code to import the dataframe data into Excel and save it:
with pd.ExcelWriter('outputfile.xlsx', engine='xlsxwriter') as writer:
df.to_excel(writer, sheet_name='Sheet_1', index=False, startrow=2)
workbook = writer.book
worksheet = writer.sheets['Sheet_1']
datetime_format = workbook.add_format({'num_format':'dd-mm-yy hh:mm:ss'})
worksheet.set_column('A:A',None,datetime_format)
The code does output the data in Excel, but the dd-mm-yy hh:mm:ss formatting is only being applied to column A (the date time column) before and after the actual dataframe date (I'm purposefully not writing the data until row 2).
When I inspect 'Format Cells' dialog in Excel, row 0 and row 1 of column A are being formatted as dd-mm-yy hh:mm:ss. In cells of the column that have datetime values, those cells are retaining the format of the original pandas dataframe column (yyyy-mm-dd hh:mm:ss:microseconds).
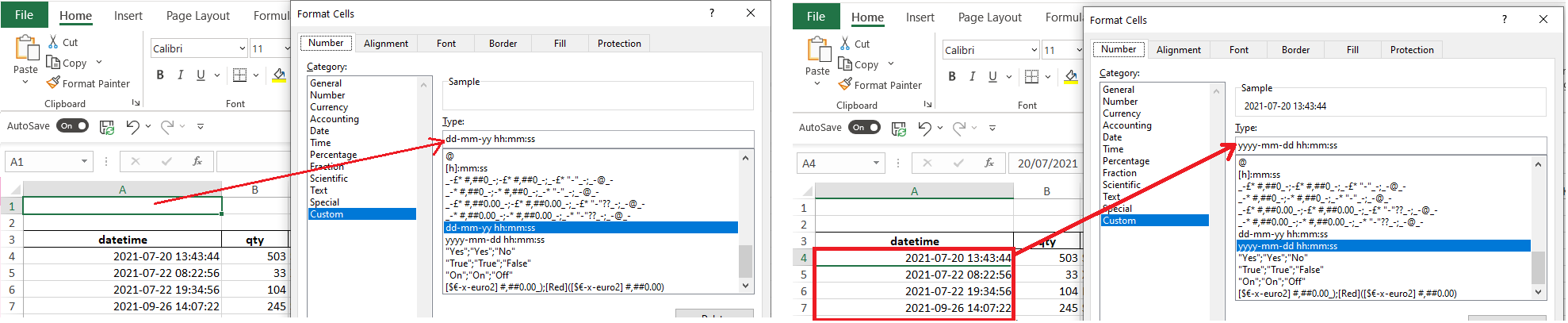
It seems as though the dataframe's original formatting is overwriting the custom formatting, despite the two lines of code defining and applying the custom formatting coming after the df.to_excel() line that writes the dataframe content to Excel.
Hoping someone might be able to spot an obvious issue here or if this is a limitation of xlsxwriter.
CodePudding user response:
As mentionned by @BigBen,