Where does SQL Server get the Estimated Number of Rows when you have AUTO_CREATE_STATISTICS turned off?
Here is an example:
Setup experiment:
USE master;
GO
IF EXISTS(SELECT * FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
ALTER DATABASE TestDatabase SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE TestDatabase;
END
GO
CREATE DATABASE TestDatabase;
GO
ALTER DATABASE TestDatabase SET AUTO_CREATE_STATISTICS OFF;
GO
USE TestDatabase;
GO
DROP TABLE IF EXISTS TestTable;
GO
CREATE TABLE TestTable
(
Id INT NOT NULL IDENTITY PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
Experiment:
Insert 200 rows:
SET NOCOUNT ON;
INSERT INTO TestTable Values('Test', 'Blah')
GO 200
Click Display Estimated Execution Plan when
highlighting the query below:
SELECT *
FROM TestTable
WHERE LastName = 'blah';
It gives me an estimated # row of 200.
Run the below query again:
SET NOCOUNT ON;
INSERT INTO TestTable Values('Test', 'Blah')
GO 200
Once again click Display Estimated Execution Plan when
highlighting the query below:
SELECT *
FROM TestTable
WHERE LastName = 'blah';
It gives me an estimated # rows of 400.
Now I run query instead of getting estimates
SELECT *
FROM TestTable
WHERE LastName = 'blah';
Now I insert another 200 rows
SET NOCOUNT ON;
INSERT INTO TestTable Values('Test', 'Blah')
GO 200
Once again click Display Estimated Execution Plan when
highlighting the query below:
SELECT *
FROM TestTable
WHERE LastName = 'blah';
It once again gives me an estimated # row of 400 instead of 600 rows.
So I run
SET NOCOUNT ON;
INSERT INTO TestTable Values('Test', 'Blah')
GO 10000
Once again click Display Estimated Execution Plan when
highlighting the query below:
SELECT *
FROM TestTable
WHERE LastName = 'blah';
Gives man an estimated plan of 400 rows instead of 10,600.
So it appears if you get the estimated number of rows before running the query, it will give you the total number of rows in the table. Once you run the query, it gives you the total number of rows on the table before running the query.
So where exactly is SQL Server getting this number from?
CodePudding user response:
When AUTO CREATE STATISTICS is disabled, SQL Server employs a "cardinality estimator" to estimate the number of rows that will be returned by a query.
The cardinality estimator makes this estimate based on a number of factors, including the data types and distributions of the columns in the table, the specific predicates used in the query, and any available statistics.
In your example, it appears that the estimator is estimating the total number of rows in the table rather than the specific predicate in the query ("LastName = 'blah'").
This is most likely due to the table's lack of statistics, which would normally be used to more accurately estimate the number of rows.
CodePudding user response:
I strongly suggest never setting AUTO_CREATE_STATISTICS to OFF so hopefully this question is just for academic interest.
SQL Server knows the table cardinality (number of rows in the table) as this is held in table metadata independent of statistics. When you say " estimated # rows of 200" etc are you referring to "estimated number of rows to be read"?
As there is no index on LastName and it has to scan the whole table to find rows matching the WHERE clause this will be the same number as table cardinality. No cardinality estimator model will assume that 100% of those rows will match LastName = 'blah' though. For 200 rows in the table I got an estimate of 53 with QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_110 and 14 (SQRT(200)) with all later ones.
Either way this is just based on a guessed proportion that will match though as (in the absence of any column statistics or constraints) there is nothing else that can be used to base this number on.
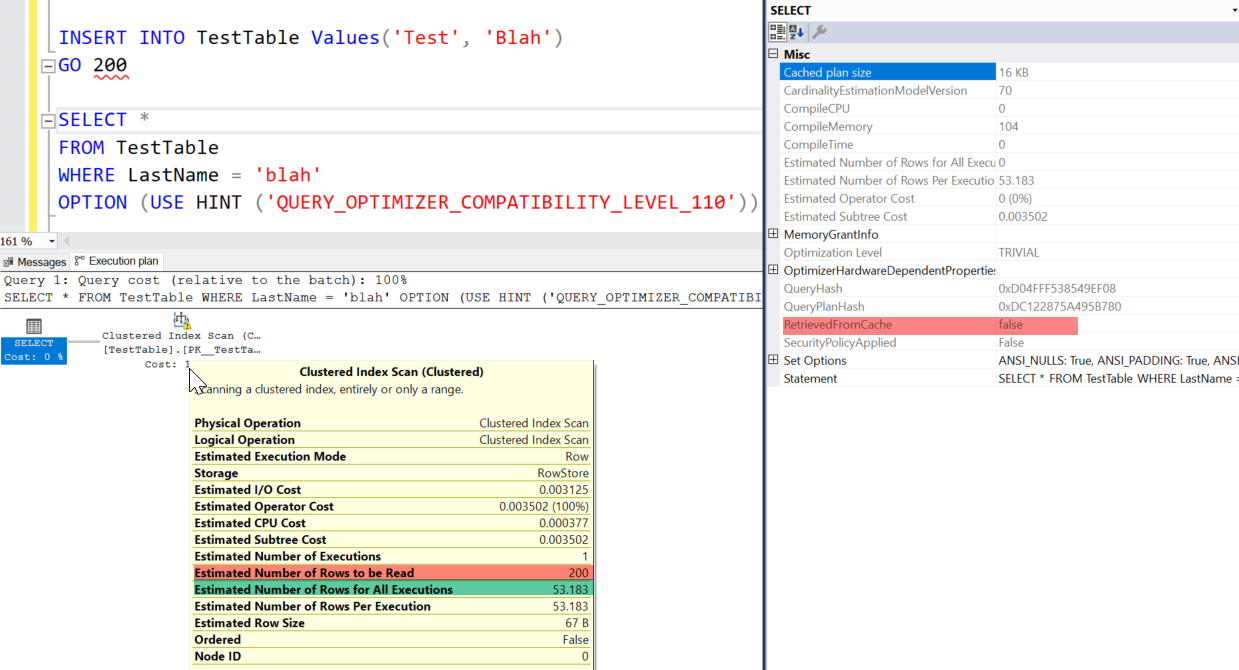
When you generate an estimated execution plan this is not stored in the plan cache. When you actually run it the plan is cached. So this is why you see estimates of "rows read" in line with actual table cardinality when all you have done so far is generate estimated plans.
It gives me an estimated # rows of 400.
Now I run query instead of getting estimates
You executed the query when the table had 400 rows and this added the execution plan to the cache (complete with 400 row estimate) - so future executions can use this cached plan.
Once the plan is in the cache you are then dependent on if number of modified rows triggers an optimality based recompile and you get a new execution plan or if it is under the threshold to just use the cached plan.
Usually adding 10,200 rows to a 400 row table would be way in excess of what is required to cross the "Recompilation Threshold" and trigger an optimality based compile. I assume it does not happen in this case as no statistics were ever used in the plan so it can not ever deem these statistics as being stale.