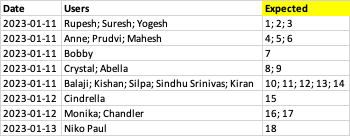
I would like to achieve the column Expected in the screenshot below. Could you please help me achieve this on Synapse Datawarehouse using the following table scripts and sample data.
Note:
- This is just a sample data set. The original Users table would have millions of rows.
- Users column can more than N number of users separated with delimiter ';'
CREATE TABLE [BTS_Test].[Users]
(
[Date] [date] NOT NULL,
[Users] [varchar](500) NOT NULL
)
WITH
(
DISTRIBUTION = ROUND_ROBIN
);
INSERT INTO [BTS_Test].[Users] VALUES('2023-01-11','Rupesh; Suresh; Yogesh');
INSERT INTO [BTS_Test].[Users] VALUES('2023-01-11','Anne; Prudvi; Mahesh');
INSERT INTO [BTS_Test].[Users] VALUES('2023-01-11','Bobby');
INSERT INTO [BTS_Test].[Users] VALUES('2023-01-11','Crystal; Abella');
INSERT INTO [BTS_Test].[Users] VALUES('2023-01-11','Balaji; Kishan; Silpa; Sindhu Srinivas; Kiran');
INSERT INTO [BTS_Test].[Users] VALUES('2023-01-12','Cindrella');
INSERT INTO [BTS_Test].[Users] VALUES('2023-01-12','Monika; Chandler');
INSERT INTO [BTS_Test].[Users] VALUES('2023-01-13','Niko Paul');
CREATE TABLE [BTS_Test].[Student]
(
[ID] [int] NOT NULL,
[StudentName] [varchar](500) NOT NULL
)
WITH
(
DISTRIBUTION = REPLICATE
);
INSERT INTO [BTS_Test].[Student] VALUES(1,'Rupesh');
INSERT INTO [BTS_Test].[Student] VALUES(2,'Suresh');
INSERT INTO [BTS_Test].[Student] VALUES(3,'Yogesh');
INSERT INTO [BTS_Test].[Student] VALUES(4,'Anne');
INSERT INTO [BTS_Test].[Student] VALUES(5,'Prudvi');
INSERT INTO [BTS_Test].[Student] VALUES(6,'Mahesh');
INSERT INTO [BTS_Test].[Student] VALUES(7,'Bobby');
INSERT INTO [BTS_Test].[Student] VALUES(8,'Crystal');
INSERT INTO [BTS_Test].[Student] VALUES(9,'Abella');
INSERT INTO [BTS_Test].[Student] VALUES(10,'Balaji');
INSERT INTO [BTS_Test].[Student] VALUES(11,'Kishan');
INSERT INTO [BTS_Test].[Student] VALUES(12,'Silpa');
INSERT INTO [BTS_Test].[Student] VALUES(13,'Sindhu Srinivas');
INSERT INTO [BTS_Test].[Student] VALUES(14,'Kiran');
INSERT INTO [BTS_Test].[Student] VALUES(15,'Cindrella');
INSERT INTO [BTS_Test].[Student] VALUES(16,'Monika');
INSERT INTO [BTS_Test].[Student] VALUES(17,'Chandler');
INSERT INTO [BTS_Test].[Student] VALUES(18,'Niko Paul');
CodePudding user response:
Here is an option using JSON to keep the sequence. Performance over millions of rows??? Just keep in mind there are penalties for storing delimited data.
Example
Select *
From [Users] A
Cross Apply (
Select Expected = string_agg(ID,';') WITHIN GROUP ( ORDER BY [key] )
From OpenJSON( '["' replace(string_escape([Users],'json'),';','","') '"]' )
Join [Student] on trim(Value)=StudentName
) B
Results
Date Users Expected
2023-01-11 Rupesh; Suresh; Yogesh 1;2;3
2023-01-11 Anne; Prudvi; Mahesh 4;5;6
2023-01-11 Bobby 7
2023-01-11 Crystal; Abella 8;9
2023-01-11 Balaji; Kishan; Silpa; Sindhu Srinivas; Kiran 10;11;12;13;14
2023-01-12 Cindrella 15
2023-01-12 Monika; Chandler 16;17
2023-01-13 Niko Paul 18
CodePudding user response:
This produces results using STRING_SPLIT and XML:
SELECT u.[DATE], u.USERS, (STUFF((SELECT ';' Y
FROM (select CAST(s.id AS VARCHAR) AS y from STRING_SPLIT (u.USERS, ';') sp
INNER JOIN STUDENT s on s.STUDENTNAME = trim(sp.Value)) X
FOR XML PATH('')) ,1,1,'')) as EXPECTED
FROM USERS u