I have to get some columns as is and some columns from a query as JSON document. The as is column names are known to me but rest are dynamic columns so there are not known beforehand.
Below is the query like
select col1,col2,col3,
sum(col4) as col4,
sum(col5) as col5
from my_table
group by col1,col2,col3;
here col4,col5 names are unknown to me as they are been fetched dynamically.
Suppost my_table data looks like
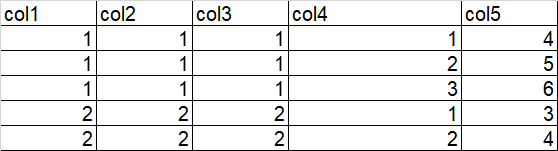
The expected result is like below

I tried
select JSON_OBJECT(*) from
(
select col1,col2,col3,
sum(col4) as col4,
sum(col5) as col5
from my_table
group by col1,col2,col3
);
But obviously it does not yield expected output. I'm on 19c DB version 19.17 Any help or suggestion would be great help!
CodePudding user response:
It's kinda hacky, but you could:
- Use
json_object(*)to convert the whole row tojson - Pass the result of this
json_transform*, which you can use to remove unwanted attributes
So you could do something like:
with rws as (
select mod ( level, 2 ) col1, mod ( level, 3 ) col2,
level col3, level col4
from dual
connect by level <= 10
), grps as (
select col1,col2,
sum(col3) as col3,
sum(col4) as col4
from rws
group by col1,col2
)
select col1,col2,
json_transform (
json_object(*),
remove '$.COL1',
remove '$.COL2'
) json_data
from grps;
COL1 COL2 JSON_DATA
---------- ---------- ------------------------------
1 1 {"COL3":8,"COL4":8}
0 2 {"COL3":10,"COL4":10}
1 0 {"COL3":12,"COL4":12}
0 1 {"COL3":14,"COL4":14}
1 2 {"COL3":5,"COL4":5}
0 0 {"COL3":6,"COL4":6}
json_transformis a 21c feature that's been backported to 19c in 19.10.
CodePudding user response:
You may achieve this by using Polymorphic Table Function available since 18c.
Define the function that will project only specific columns and serialize others into JSON. An implementation is below.
- PTF package (function implementation).
create package pkg_jsonify as /*Package to implement PTF. Functions below implement the API described in the DBMS_TF package*/ function describe( tab in out dbms_tf.table_t, keep_cols in dbms_tf.columns_t ) return dbms_tf.describe_t ; procedure fetch_rows; end pkg_jsonify; /
create package body pkg_jsonify as function describe( tab in out dbms_tf.table_t, keep_cols in dbms_tf.columns_t ) return dbms_tf.describe_t as add_cols dbms_tf.columns_new_t; new_col_cnt pls_integer := 0; begin for i in 1..tab.column.count loop /*Initially remove column from the output*/ tab.column(i).pass_through := FALSE; /*and keep it in the row processing (to be available for serialization*/ tab.column(i).for_read := TRUE; for j in 1..keep_cols.count loop /*If column is in a projection list, then remove it from processing and pass it as is*/ if tab.column(i).description.name = keep_cols(j) then tab.column(i).pass_through := TRUE; /*Skip column in the row processing (JSON serialization)*/ tab.column(i).for_read := FALSE; end if; end loop; end loop; /*Define new output column*/ add_cols := dbms_tf.columns_new_t( 1 => dbms_tf.column_metadata_t( name => 'JSON_DOC_DATA', type => dbms_tf.type_clob ) ); /*Return the list of new cols*/ return dbms_tf.describe_t( new_columns => add_cols ); end; procedure fetch_rows /*Process rowset and serialize cols*/ as rowset dbms_tf.row_set_t; num_rows pls_integer; new_col dbms_tf.tab_clob_t; begin /*Get rows*/ dbms_tf.get_row_set( rowset => rowset, row_count => num_rows ); for rn in 1..num_rows loop /*Calculate new column value in the same row*/ new_col(rn) := dbms_tf.row_to_char( rowset => rowset, rid => rn, format => dbms_tf.FORMAT_JSON ); end loop; /*Put column to output*/ dbms_tf.put_col( columnid => 1, collection => new_col ); end; end pkg_jsonify; /
- PTF function definition based on the package.
create function f_cols_to_json(tab in table, cols in columns) /*Function to serialize into JSON using PTF*/ return table pipelined row polymorphic using pkg_jsonify; /
- Demo.
create table sample_tab as select trunc(level/10) as id , mod(level, 3) as id2 , level as val1 , level * level as val2 from dual connect by level < 40
with prep as ( select id , id2 , sum(val1) as val1_sum , max(val2) as val2_max from sample_tab group by id , id2 ) select * from table(f_cols_to_json(prep, columns(id, id2)))
| ID | ID2 | JSON_DOC_DATA |
|---|---|---|
| 0 | 1 | {"VAL1_SUM":12, "VAL2_MAX":49} |
| 0 | 2 | {"VAL1_SUM":15, "VAL2_MAX":64} |
| 0 | 0 | {"VAL1_SUM":18, "VAL2_MAX":81} |
| 1 | 1 | {"VAL1_SUM":58, "VAL2_MAX":361} |
| 1 | 2 | {"VAL1_SUM":42, "VAL2_MAX":289} |
| 1 | 0 | {"VAL1_SUM":45, "VAL2_MAX":324} |
| 2 | 2 | {"VAL1_SUM":98, "VAL2_MAX":841} |
| 2 | 0 | {"VAL1_SUM":72, "VAL2_MAX":729} |
| 2 | 1 | {"VAL1_SUM":75, "VAL2_MAX":784} |
| 3 | 0 | {"VAL1_SUM":138, "VAL2_MAX":1521} |
| 3 | 1 | {"VAL1_SUM":102, "VAL2_MAX":1369} |
| 3 | 2 | {"VAL1_SUM":105, "VAL2_MAX":1444} |
with prep as ( select id , id2 , sum(val1) as val1_sum , max(val2) as val2_max from sample_tab group by id , id2 ) select * from table(f_cols_to_json(prep, columns(id)))
| ID | JSON_DOC_DATA |
|---|---|
| 0 | {"ID2":1, "VAL1_SUM":12, "VAL2_MAX":49} |
| 0 | {"ID2":2, "VAL1_SUM":15, "VAL2_MAX":64} |
| 0 | {"ID2":0, "VAL1_SUM":18, "VAL2_MAX":81} |
| 1 | {"ID2":1, "VAL1_SUM":58, "VAL2_MAX":361} |
| 1 | {"ID2":2, "VAL1_SUM":42, "VAL2_MAX":289} |
| 1 | {"ID2":0, "VAL1_SUM":45, "VAL2_MAX":324} |
| 2 | {"ID2":2, "VAL1_SUM":98, "VAL2_MAX":841} |
| 2 | {"ID2":0, "VAL1_SUM":72, "VAL2_MAX":729} |
| 2 | {"ID2":1, "VAL1_SUM":75, "VAL2_MAX":784} |
| 3 | {"ID2":0, "VAL1_SUM":138, "VAL2_MAX":1521} |
| 3 | {"ID2":1, "VAL1_SUM":102, "VAL2_MAX":1369} |
| 3 | {"ID2":2, "VAL1_SUM":105, "VAL2_MAX":1444} |