Currently working to implement some fuzzy matching logic to group together emails with similar patterns and I need to improve the efficiency of part of the code but not sure what the best path forward is. I use a package to output a pandas dataframe that looks like this:
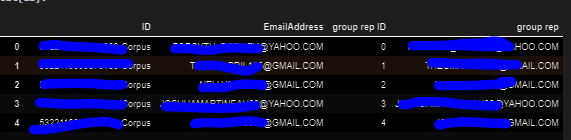
I redacted the data, but it's just four columns with an ID #, the email associated with a given ID, a group ID number that identifies the cluster a given email falls into, and then the group rep which is the most mathematically central email of a given cluster.
What I want to do is count the number of occurrences of each distinct element in the group rep column and create a new dataframe that's just two columns with one column having the group rep email and then the second column having the corresponding count of that group rep in the original dataframe. It should look something like this:
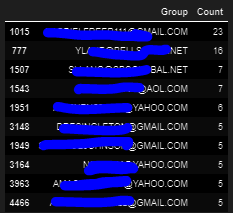
As of now, I'm converting my group reps to a list and then using a for-loop to create a list of tuples(I think?) with each tuple containing a centroid email group identifiers and the number of times that identifier occurs in the original df (aka the number of emails in the original data that belong to that centroid email's group). The code looks like this:
groups = list(df['group rep'].unique())
# preparing list of tuples with group count
req_groups = []
for g in groups:
count = (g, df['group rep'].value_counts()[g])
#print(count)
req_groups.append(count)
print(req_groups)
Unfortunately, this operation takes far too long. I'm sure there's a better solution, but could definitely use some help finding a path forward. Thanks in advance for your help!
CodePudding user response:
Can you not use df.groupby('group rep').count()
CodePudding user response:
Like you did not provide a dataframe to start working with, let's consider the following dataframe :
email
0 [email protected]
1 [email protected]
2 [email protected]
3 [email protected]
4 [email protected]
5 [email protected]
6 [email protected]
Proposed script
import pandas as pd
import operator
m = {'email':['[email protected]','[email protected]','[email protected]','[email protected]',
'[email protected]','[email protected]','[email protected]']}
df = pd.DataFrame(m)
counter = pd.DataFrame.from_dict({c: [operator.countOf(df['email'], c)] for c in df['email'].unique()})
cnt_df = counter.T.rename(columns={0:'count'})
print(cnt_df)
Result
count
[email protected] 1
[email protected] 2
[email protected] 2
[email protected] 1
[email protected] 1