I have had this question a while but never done anything about it, when mapping some elements for UI tests i sometimes come across elements that return 2 identical results.
We have got around this in the past by using findelements and then using an index [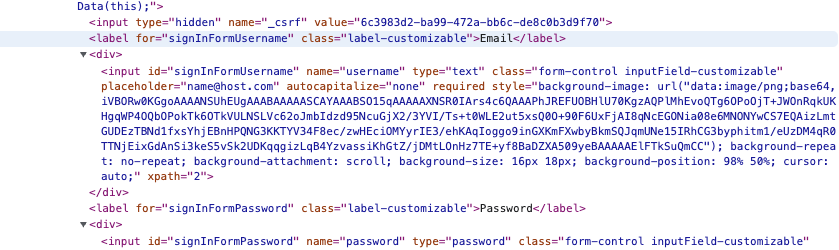
and if i use some xpath like
//input[@name='username']
i'm expecting only to get 1 element in return, but using the tool Chropath i can see that i get 2 elements in return
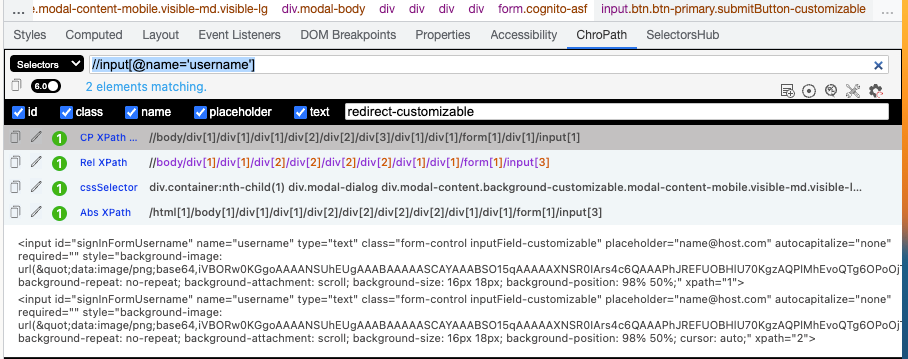
These elements look identical, one is not hidden etc. I have never understood why this is happening, because if i use a findelement. I get a element not interactable error as i guess the driver cant decide which one to use? or they are in the way of one another.
So the workaround i have always used is
return self.browser.find_elements(by=By.XPATH, value="//input[@name='username']")[1]
when i realisticly should be able to use
return self.browser.find_element(by=By.XPATH, value="//input[@name='username']")
Any help to understand why this is would be greatly appreciated
CodePudding user response:
It is possible you can have more than one same element on the page with same name attribute. One must be hidden.
If you want to access the first one use following xpath.
return self.browser.find_element(by=By.XPATH, value="(//input[@name='username'])[1]")
If you want to access last one use following
return self.browser.find_element(by=By.XPATH, value="(//input[@name='username'])[last()]")
CodePudding user response:
Well in the strictest sense of way, no two elements have the same xpath. If you look at the absolute path you will find the difference. The key is to find a path which is unique. In many case, you will find a web page where you find many textboxes/labels/dropdowns that have the same ids but are only differentiated by their absolute path.
Most of the times such things depends on the framework used to develop the webpage and also developer's preference. An application developed in React will have a different DOm structure than one developed using Angular, for instance.
Yes you are correct that it becomes difficult to find out which is the element of interest in such situations. In such cases do not only depend on the particular element but add either a parent/wibling or ancestor to access the element. Although it might take some time and will jot be straightforward but it will be possible to find a unique xpath most of the times.
There are some test automation tools like Ranorex that have an object browser (objext spy as it is called) that can be used to pin on any web element and access its properties like hidden/visible/enabled etc. But such tools are not free :(
CodePudding user response:
It's quite often occurres that multiple elements will match the same locator.
For example several code blocks may be implemented for login: one for computer browser, another for mobile browser etc. The proper elements will be presented according to what you use to browse that page.
Selenium find_element always returns first element found matching the passed locator on the page.
So, in case the first matching element is hidden return self.browser.find_element(by=By.XPATH, value="//input[@name='username']") will always retunt that hidden element.
You will need to make your locator more precise to match the desired web element.
Locator like "(//input[@name='username'])[2]" may be good, but it's better to use unique parent element here, something like "//div[@class='pc_modal']//input[@name='username']" so your code would be something like this:
return self.browser.find_element(By.XPATH, "//div[@class='pc_modal']//input[@name='username']")