I have a data frame which I groupBy Date and name and I aggregate the average of price.
df.filter("some filter")
.withColumn("price_int", df.print.cast('integer'))
.groupBy("Date", 'name')
.agg(avg(col('price_int')))
I want to get the max, and stddev of price_int column.
df.filter("some filter")
.withColumn("price_int", df.print.cast('integer'))
.groupBy("Date", 'name')
.agg(avg(col('price_int'),
max(col('price_int'),
stddev(col('price_int'),
)))
But when I add max(col('price_int), I get error saying Column is not iterable
And when I add stddev(col('price_int), I get error saying 'stdev is not defined'
Can you please tell me how can I get 'max' and 'standard dev' of the column 'price_int'?
CodePudding user response:
I'm skeptical about where the issue is, as the code you provided seems to have syntax messed up, but in any case - the below would work:
from pyspark.sql import functions as F
df.filter("some filter")
.withColumn("price_int", df.print.cast('integer'))
.groupBy("Date", 'name')
.agg(F.avg(F.col('price_int')).alias("Average"), F.stddev(F.col("price_int")).alias("Std_Deviation"), F.max(F.col("price_int")).alias("Maximum"))
Worked for me:
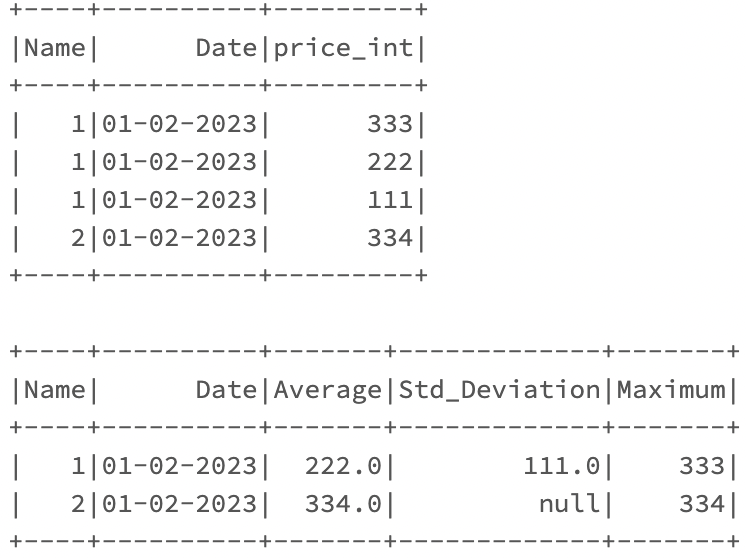
Also, note Spark has 2 different standard deviation functions:
stddev() or stddev_samp() - returns the unbiased sample standard deviation of the expression in a group
stddev_pop() - returns population standard deviation of the expression in a group.