Let's suppose there are 12 folders on my Container so i have to copy the folder names to a csv file.
In first step i used a getmetadata activity to get the folder names from the container
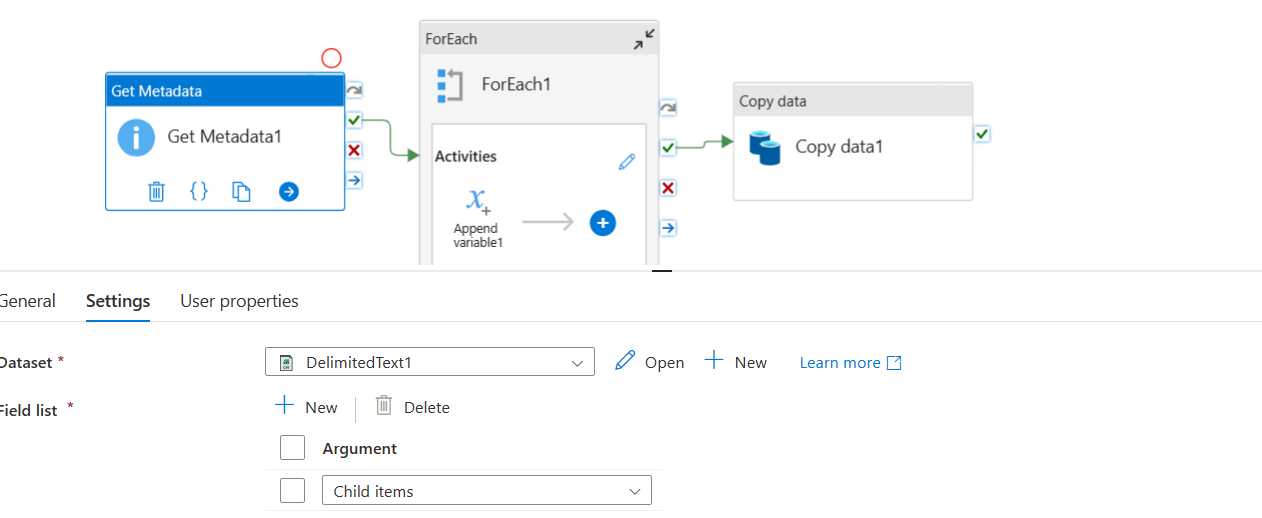
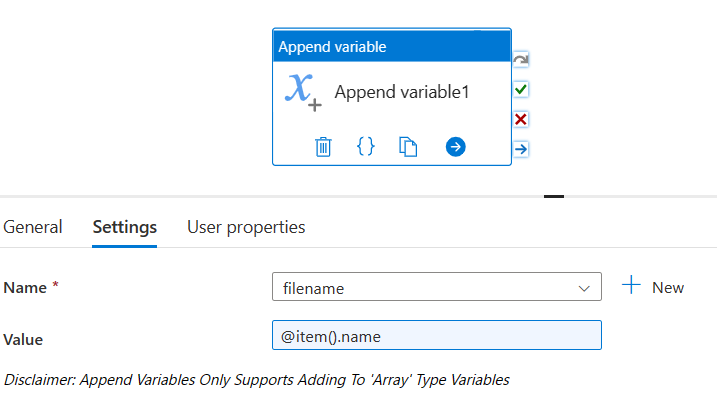
In second step i used a Foreach activity and pass @activity('Get Metadata1').output.childItems as items a) Inside foreach i used append varriable activity and append the item().name into a varriable Filename as shown in screenshot.So filename varriable is of array type and it is used to store an array of folder names in Container.
In Third step i used a copy activity it will copy folder names from filename varriable in append activity and will store data into a sink(csv file).
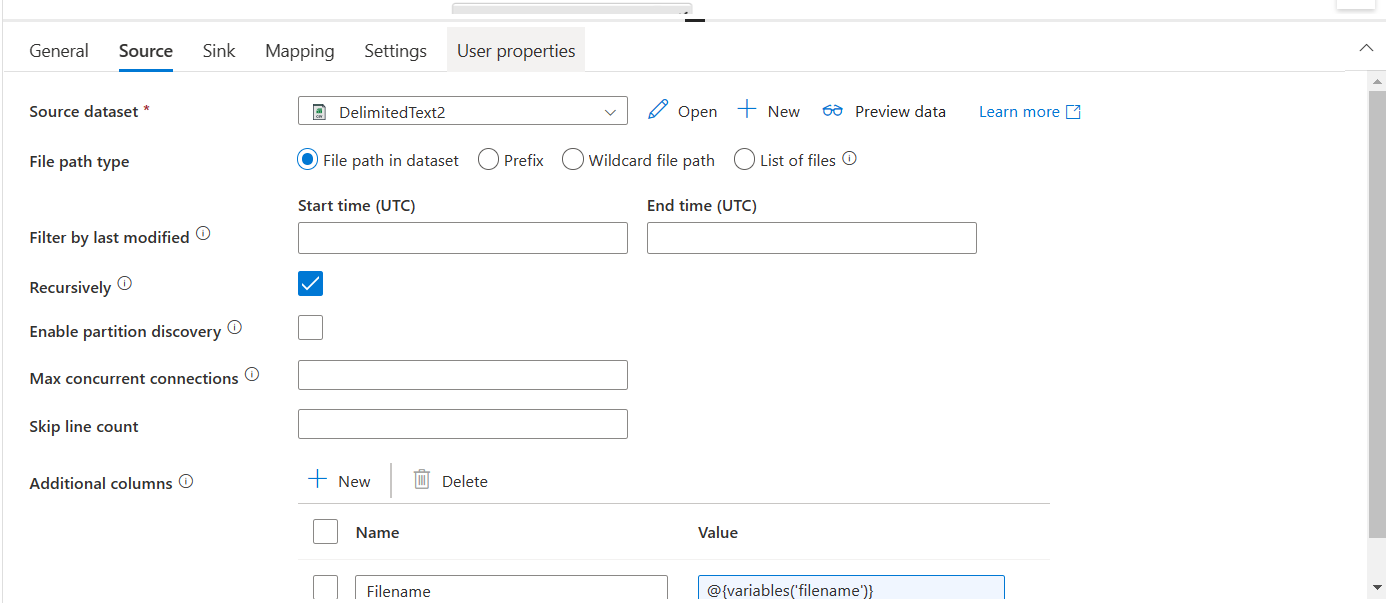
a) The source dataset is a dummy csv file
b) then I check the Mapping
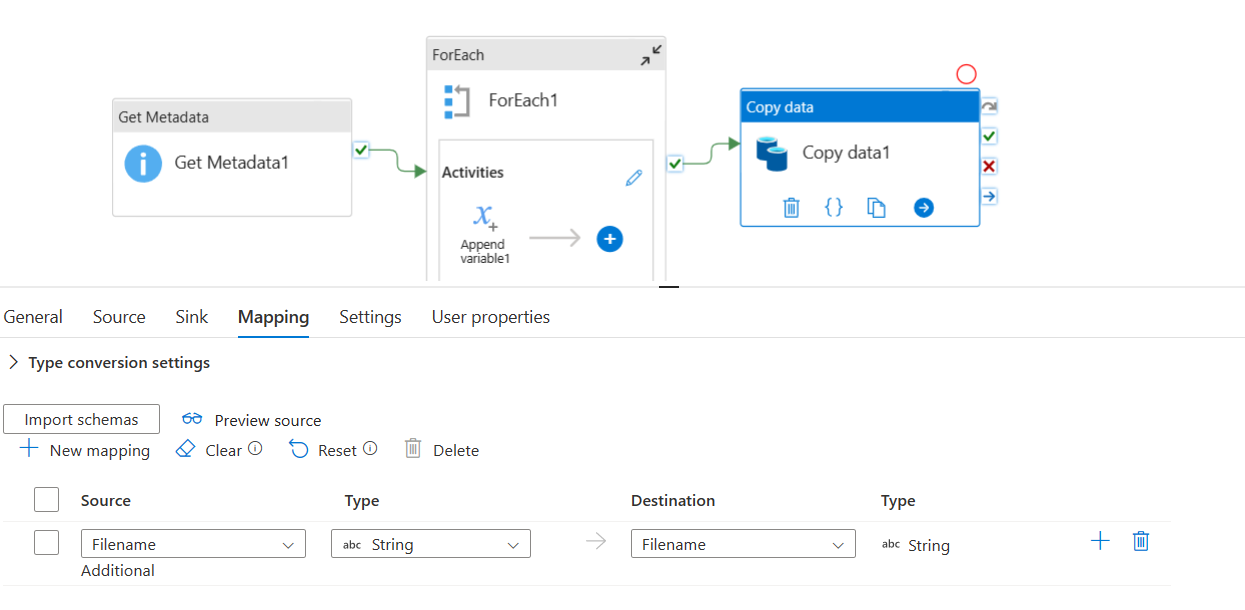
Error
After this when i debug pipeline i am not able to see any foldername on my storage location
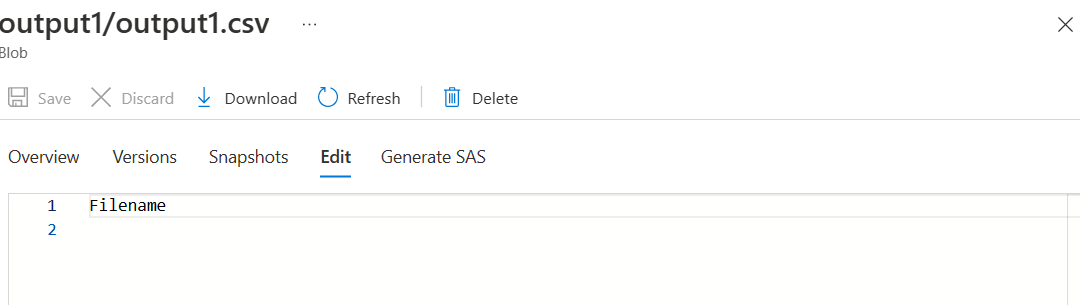
CodePudding user response:
You have to deselect the first row as header option in your source dataset. Also change the quote character and escape character to none. The data will be written successfully to your sink file as shown below.
However, if you want to write all the file names to a single column, you can use the following procedure instead:
- I have the following folders in my source:
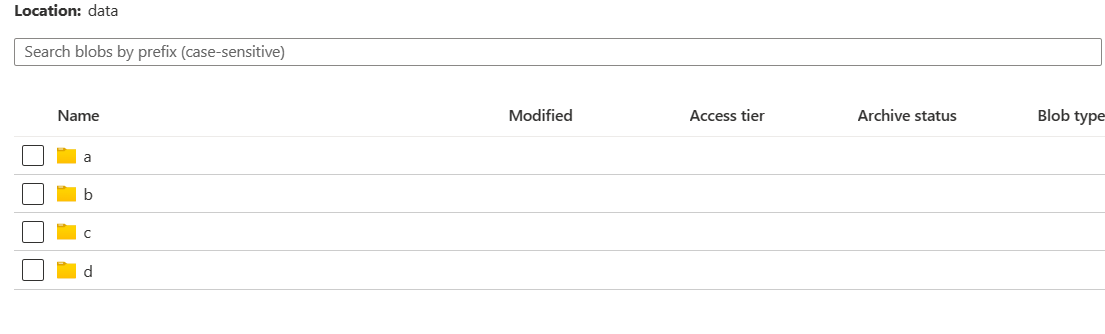
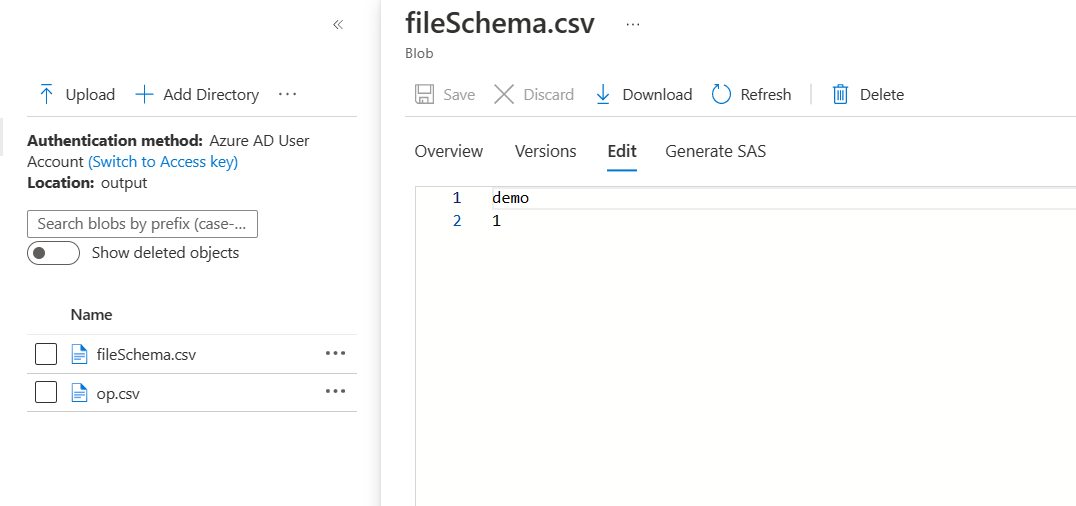
- In the dummy source file, I have the data as following:
- The following is the source dataset JSON:
{
"name": "source1",
"properties": {
"linkedServiceName": {
"referenceName": "adls",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobFSLocation",
"fileSystem": "data"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"firstRowAsHeader": true,
"quoteChar": "\""
},
"schema": [
{
"type": "String"
}
]
},
"type": "Microsoft.DataFactory/factories/datasets"
}
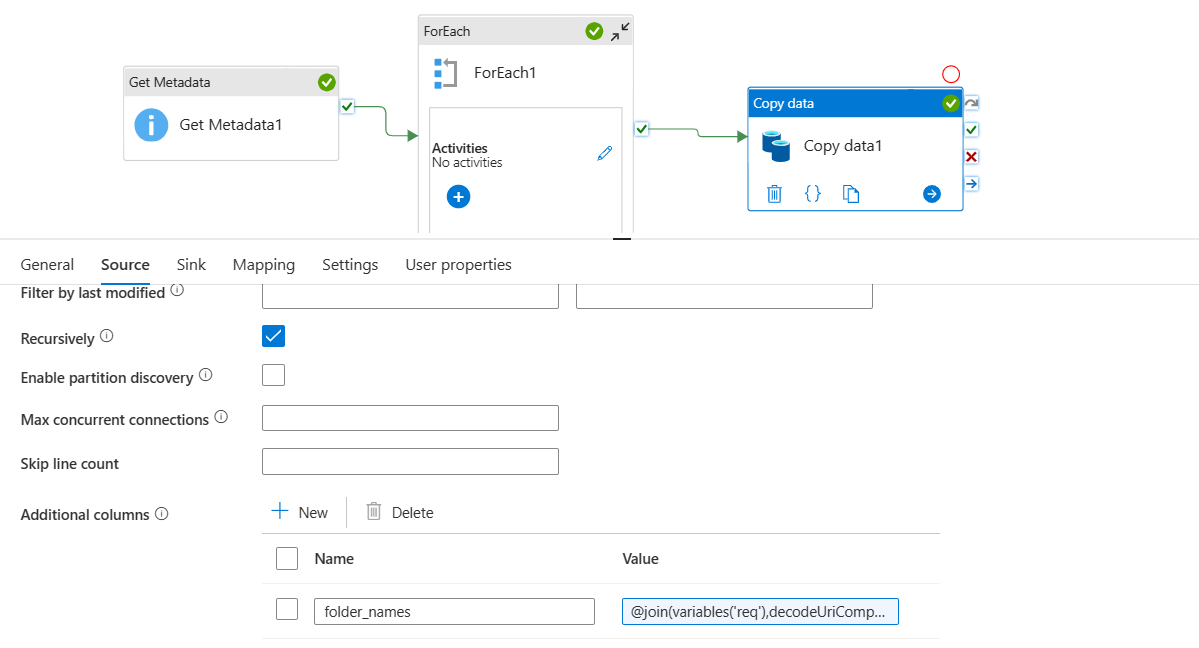
- Now, after using append variable activity to get all the folder names in a single array, use the following dynamic content in new column
folder_names.
@join(variables('req'),decodeUriComponent('
'))
- The following is the sink dataset JSON:
{
"name": "output",
"properties": {
"linkedServiceName": {
"referenceName": "adls",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobFSLocation",
"fileName": "op.csv",
"fileSystem": "output"
},
"columnDelimiter": ",",
"escapeChar": "",
"firstRowAsHeader": true,
"quoteChar": ""
},
"schema": []
}
}
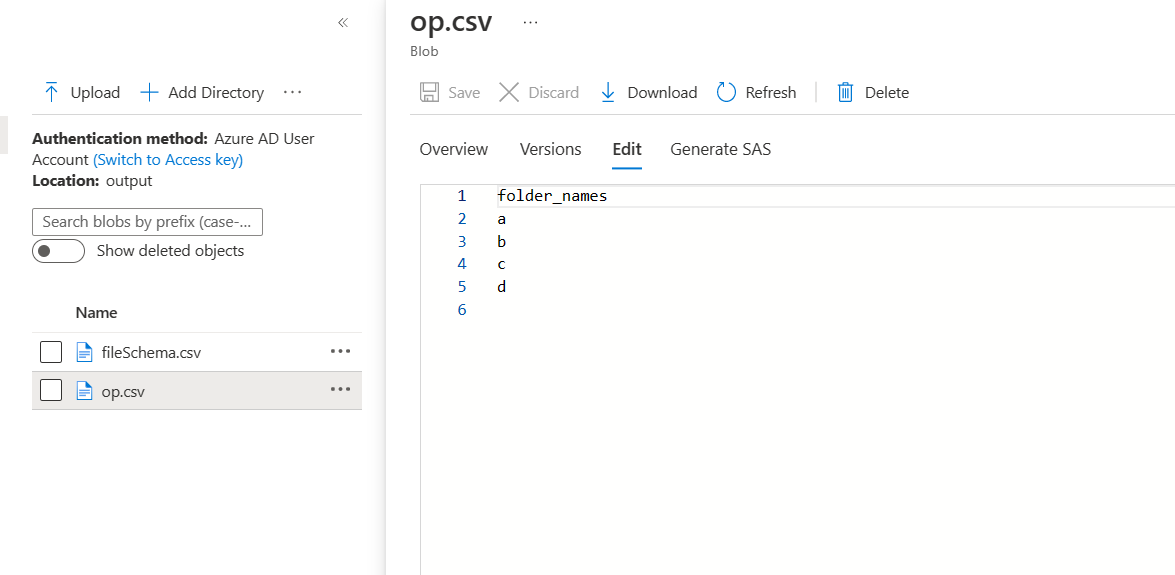
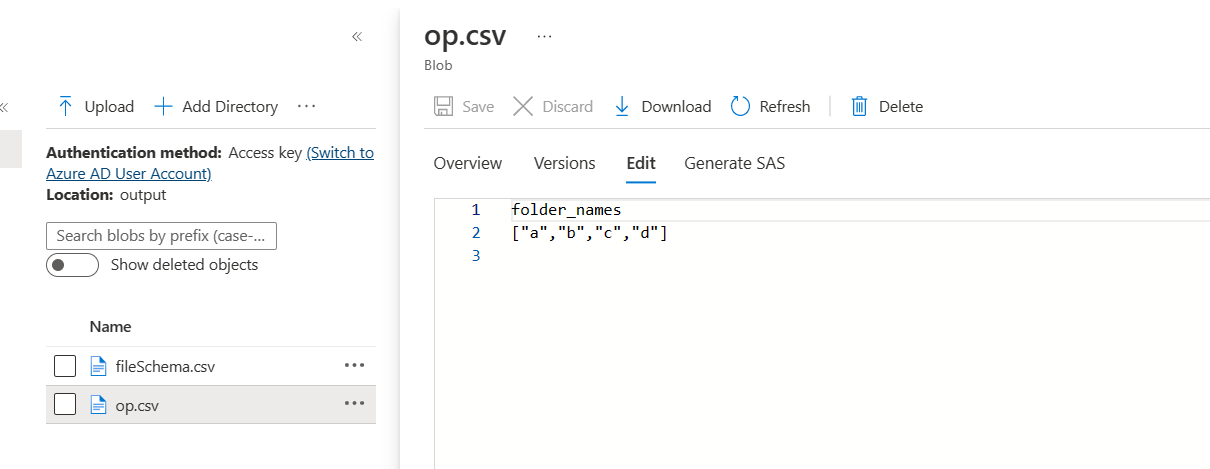
- When I run the pipeline, I would get the data as following: