I'm trying to set up a simple webscraping script to pull every hyperlink from the discover cards on Bandcamp.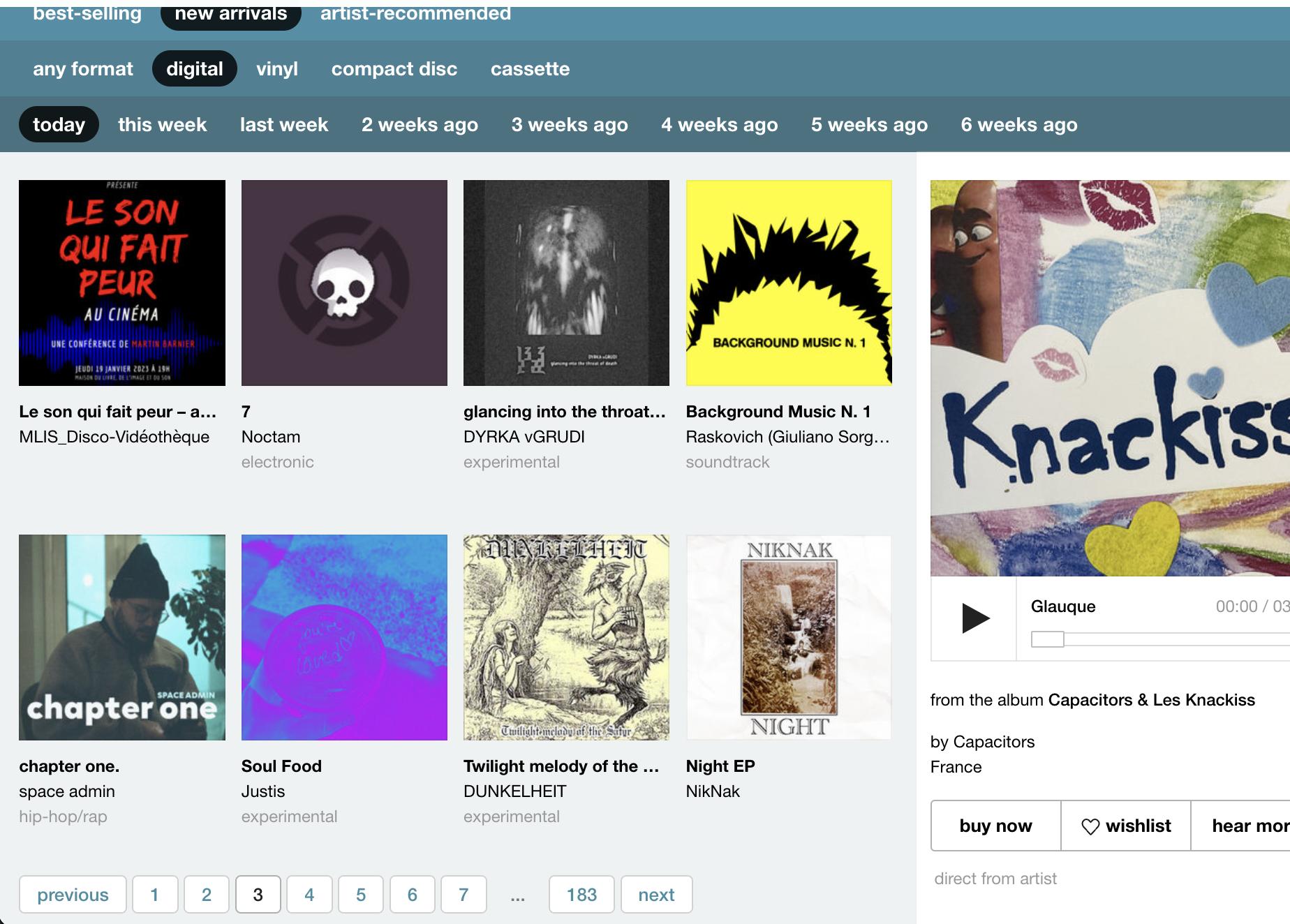
Here is my code:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.select import Select
browser = webdriver.Chrome()
all_links = []
page = 1
url = "https://bandcamp.com/?g=all&s=new&p=0&gn=0&f=digital&w=-1"
browser.get(url)
while page < 6:
page = 1
# wait until discover cards are loaded
test = WebDriverWait(browser, 20).until(EC.element_to_be_clickable(
(By.XPATH, '//*[@id="discover"]/div[9]/div[2]/div/div[1]/div/table/tbody/tr[1]/td[1]/a/div')))
# scrape hyperlinks for each of the 8 albums shown
titles = browser.find_elements(By.CLASS_NAME, "item-title")
links = [title.get_attribute('href') for title in titles[-8:]]
all_links = all_links links
print(links)
# pagination - click through the page buttons as the links are scraped
page_nums = browser.find_elements(By.CLASS_NAME, 'item-page')
for page_num in page_nums:
if page_num.text.isnumeric():
if int(page_num.text) == page:
page_num.click()
time.sleep(20) # I've tried multiple long wait times as well as WebDriverWaits on different elements to see if the HTML will update, but I haven't seen a positive effect
break
I'm using print(links) to see where this is going wrong. In the selenium browser, it clicks through the pages well. Note that pagination via the url parameters doesn't seem possible as the discover cards often won't load unless you click the page buttons towards the bottom of my picture. BetterSoup and Requests don't work either for the same reason. The print function is returning the following:
['https://neubauten.bandcamp.com/album/stimmen-reste-musterhaus-7?from=discover-new', 'https://cirka1.bandcamp.com/album/time?from=discover-new', 'https://futuramusicsound.bandcamp.com/album/yoga-meditation?from=discover-new', 'https://deathsoundbatrecordings.bandcamp.com/album/real-mushrooms-dsbep092?from=discover-new', 'https://riacurley.bandcamp.com/album/take-me-album?from=discover-new', 'https://terracuna.bandcamp.com/album/el-origen-del-viento?from=discover-new', 'https://hyper-music.bandcamp.com/album/hypermusic-vol-4?from=discover-new', 'https://defisis1.bandcamp.com/album/priceless?from=discover-new']
['https://jarnosalo.bandcamp.com/album/here-lies-ancient-blob?from=discover-new', 'https://andreneitzel.bandcamp.com/album/allegasi-gold-2?from=discover-new', 'https://moonraccoon.bandcamp.com/album/prequels?from=discover-new', 'https://lolivone.bandcamp.com/album/live-at-the-berklee-performance-center?from=discover-new', 'https://nilswrasse.bandcamp.com/album/a-calling-from-the-desert-to-the-sea-original-motion-picture-soundtrack?from=discover-new', 'https://whitereaperaskingride.bandcamp.com/album/asking-for-a-ride?from=discover-new', 'https://collageeffect.bandcamp.com/album/emerald-network?from=discover-new', 'https://foxteethnj.bandcamp.com/album/through-the-blue?from=discover-new']
['https://jarnosalo.bandcamp.com/album/here-lies-ancient-blob?from=discover-new', 'https://andreneitzel.bandcamp.com/album/allegasi-gold-2?from=discover-new', 'https://moonraccoon.bandcamp.com/album/prequels?from=discover-new', 'https://lolivone.bandcamp.com/album/live-at-the-berklee-performance-center?from=discover-new', 'https://nilswrasse.bandcamp.com/album/a-calling-from-the-desert-to-the-sea-original-motion-picture-soundtrack?from=discover-new', 'https://whitereaperaskingride.bandcamp.com/album/asking-for-a-ride?from=discover-new', 'https://collageeffect.bandcamp.com/album/emerald-network?from=discover-new', 'https://foxteethnj.bandcamp.com/album/through-the-blue?from=discover-new']
['https://jarnosalo.bandcamp.com/album/here-lies-ancient-blob?from=discover-new', 'https://andreneitzel.bandcamp.com/album/allegasi-gold-2?from=discover-new', 'https://moonraccoon.bandcamp.com/album/prequels?from=discover-new', 'https://lolivone.bandcamp.com/album/live-at-the-berklee-performance-center?from=discover-new', 'https://nilswrasse.bandcamp.com/album/a-calling-from-the-desert-to-the-sea-original-motion-picture-soundtrack?from=discover-new', 'https://whitereaperaskingride.bandcamp.com/album/asking-for-a-ride?from=discover-new', 'https://collageeffect.bandcamp.com/album/emerald-network?from=discover-new', 'https://foxteethnj.bandcamp.com/album/through-the-blue?from=discover-new']
['https://finitysounds.bandcamp.com/album/kreme?from=discover-new', 'https://mylittlerobotfriend.bandcamp.com/album/amen-break?from=discover-new', 'https://electrinityband.bandcamp.com/album/rise?from=discover-new', 'https://abyssal-void.bandcamp.com/album/ritualist?from=discover-new', 'https://plataformarecs.bandcamp.com/album/v-a-david-lynch-experience?from=discover-new', 'https://hurricaneturtles.bandcamp.com/album/industrial-synth?from=discover-new', 'https://blackwashband.bandcamp.com/album/2?from=discover-new', 'https://worldwide-bitchin-records.bandcamp.com/album/wack?from=discover-new']
Each time it correctly pulls the first 8 albums on page 1, then for pages 2-4 it repeats the 8 albums on page 2, for pages 5-7 it repeats the 8 albums on page 5, and so on. Even though the page is updating (and the url changes) in the selenium browser, for some reason selenium is not recognizing any changes to the html so it repeats the same titles. Any idea where I've gone wrong?
CodePudding user response:
Your definition of titles, i.e.
titles = browser.find_elements(By.CLASS_NAME, "item-title")
is a bad idea because item-title is the class of many elements in the page. Then another bad idea is to pick titles[-8:]. It may sounds good because you think ok each time I click a page the new elements are added at the end, but this is not always the case. Your case is one of those were elements are not added sequentially.
So let's start by considering a class exclusive of cards. For example discover-item. Then open the DevTools, press CTRL F and enter .discover-item. When the url is first loaded, it will find 8 results. Now click next page, now it finds 16 results, click again and will find 24 results. To better see what's going I suggest you to run the following each time you click on the "next" button.
el = driver.find_elements(By.CSS_SELECTOR, '.discover-item')
for i,e in enumerate(el):
print(i,e.get_attribute('innerText').replace('\n',' - '))
In particular, when arriving to page 3, you will see that the first item shown in page 1 (which in my case is 0 and friends - Jacob Stanley - alternative), is now printed at a different position (in my case 8 and friends - Jacob Stanley - alternative). What happened is that the items of page 3 were added at the beginning of the list, and so you can see why titles[-8:] was a bad choice.
So a better choice is to consider all cards each time you go to the next page, instead of the last 8 only (notice that the HTML of this site can contain no more than 24 cards), and then add all current cards to a set (since a set cannot contain duplicates, only new elements will be added).
# scroll to cards
cards = WebDriverWait(driver,20).until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, ".discover-item")))
driver.execute_script('arguments[0].scrollIntoView({block: "center", behavior: "smooth"});', cards[0])
time.sleep(1)
items = set()
while 1:
links = driver.find_elements(By.CSS_SELECTOR, '.discover-item .item-title')
# extract info and store it
for idx,card in enumerate(cards):
tit_art_gen = card.get_attribute('innerText').replace('\n',' - ')
href = links[idx].get_attribute('href')
# print(idx, tit_art_gen)
items.add(tit_art_gen ' - ' href)
# click 'next' button if it is not disabled
next_button = driver.find_element(By.XPATH, "//a[.='next']")
if 'disabled' in next_button.get_attribute('class'):
print('last page reached')
break
else:
next_button.click()
# wait until new elements are loaded
cards_new = cards.copy()
while cards_new == cards:
cards_new = driver.find_elements(By.CSS_SELECTOR, '.discover-item')
time.sleep(.5)
cards = cards_new.copy()