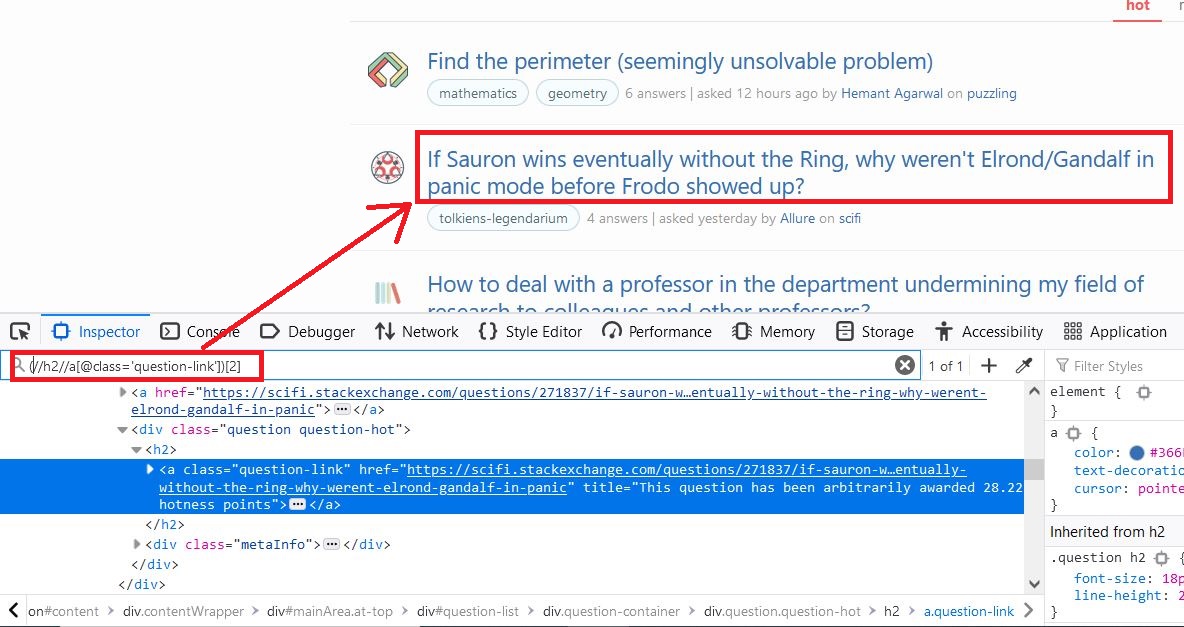
I am using this code, but it's not working but xpath in the picture is correct. I am not allowed to use (//h2//a[@class='question-link'])[2] because I need to use previous webelement:
driver.get("https://stackexchange.com/");
WebElement e = driver.findElement(By.xpath("//h2//a[@class='question-link']"));
WebElement f=e.findElement(By.xpath(".[2]"));
System.out.println(f.getText());
CodePudding user response:
Instead of again writing Webelement f write the complete xpath including [2] in Webelement e itself.
CodePudding user response:
Here is an example in Python using Selenium to extract the text from the second link using a previous WebElement:
from selenium import webdriver
initialize the browser
driver = webdriver.Firefox()
navigate to the website
driver.get("https://www.example.com")
locate the previous WebElement
previous_element = driver.find_element_by_css_selector("#element_id")
locate the second link relative to the previous WebElement
second_link = previous_element.find_elements_by_tag_name("a")[1]
extract the text from the second link
text = second_link.text
close the browser
driver.quit()
Note: Replace #element_id with the actual id of the previous WebElement and make sure to install the Selenium library if not already installed.