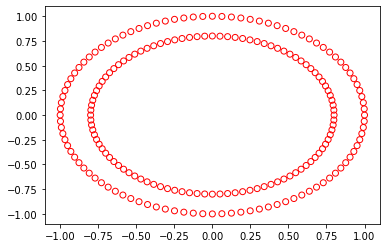
I actually wanted to generate 3 circles one inside the another with three different classes (class0, class1, class2) in python(that is first the bigger circle then inside it the second biggest circle and inside that the third circle). I am only able to generate 2 circles with two classes from the code below. Could anyone please help me with that?
import numpy as np
import pylab as pl
import sklearn.metrics as sm
from sklearn.datasets import make_circles
X, y = make_circles(n_samples=200)
print(X)
print(y)
plt.scatter(X[:,0],X[:,1], marker='o', facecolors='none', edgecolor='r')
CodePudding user response:
Probably there is a more polite way to proceed, but here I show a practical way to do it.
Basically you can generate another two circles with the function make_circles but playing with another hyperparameter, the factor.
What I do, is generating the same main circle, and then a new circle that is multiplied by the factor value (0.6 in my case).
Here is the code:
X, y = make_circles(n_samples=200)
z, w = make_circles(n_samples=200, factor=0.6)
plt.scatter(X[:,0],X[:,1], facecolors='none', edgecolor='r')
plt.scatter(z[:,0],z[:,1], facecolors='none', edgecolor='r')
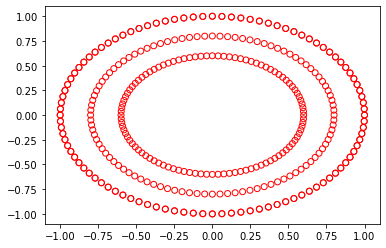
If you want to change the radius of the new circle, play with the factor.
The only problem of this code is that the big circle is duplicated (plotted twice), but, since they are overlapped, there is no visual problem.
CodePudding user response:
According to the documentations of 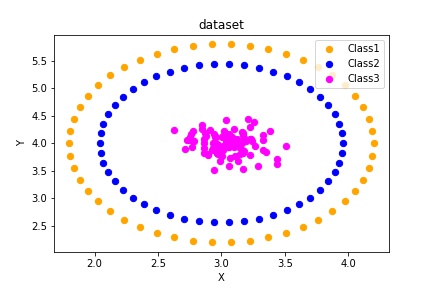
Another ways is to use two make_circle functions to generate 4 circles but using 3 of them.
import sklearn.datasets as ds
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
data, labels = ds.make_circles(n_samples=100,
shuffle=True,
noise=0.01,
random_state=42)
data2, labels2 = ds.make_circles(n_samples=100,
shuffle=True,
noise=0.0,
random_state=42)
data2 = data2 * [1.2, 1.8]
then plot results using:
fig, ax = plt.subplots()
colours = ["orange", "blue"]
label_name = ["Class1", "Class2"]
ax.scatter(data[labels==0, 0], data[labels==0, 1], color='red'
,s=40)
ax.scatter(data[labels==1, 0], data[labels==1, 1], color='green'
,s=40)
ax.scatter(data2[labels2==0, 0], data2[labels2==0, 1], color='blue',
s=40)
ax.set(xlabel='X',
ylabel='Y',
title='dataset')
ax.legend(loc='upper right')
Then the results are represented as below:
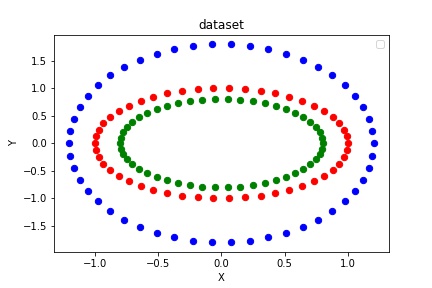
if you want to change the size of circle(3rd circle, here the outer one), you can multiply by different coefficients.
data2 = data2 * [a1, a2]
where a1 and a2 can be any values but perfectly between 0 and 2. if the values are below 1, the circles will put inner other circles and vice versa.