i was trying to open a PDF using python library PyPDF2 in AWS Lambda but its giving me access denied
Code
from PyPDF2 import PdfFileReader
pdf = PdfFileReader(open('S3 FILE URL', 'rb'))
if pdf.isEncrypted:
pdf.decrypt('')
width = int(pdf.getPage(0).mediaBox.getWidth())
height = int(pdf.getPage(0).mediaBox.getHeight())
my bucket permission
Block all public access
Off
Block public access to buckets and objects granted through new access control lists (ACLs)
Off
Block public access to buckets and objects granted through any access control lists (ACLs)
Off
Block public access to buckets and objects granted through new public bucket or access point policies
Off
Block public and cross-account access to buckets and objects through any public bucket or access point policies
Off
CodePudding user response:
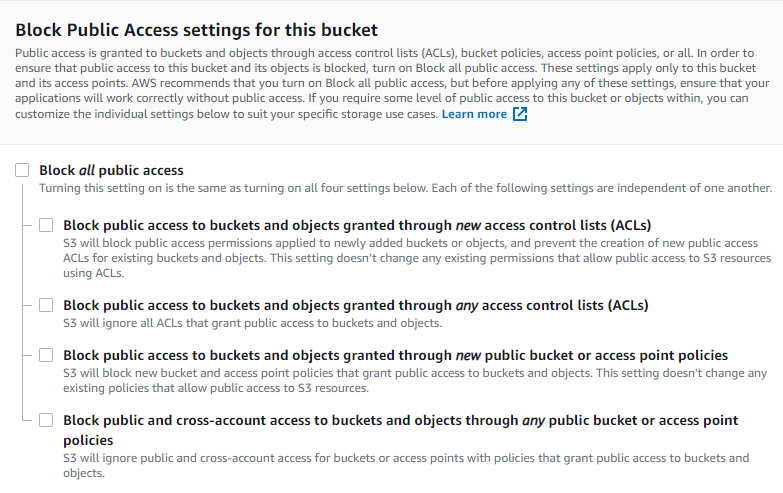
I believe you have to make changes in this section of your S3 bucket in the AWS console. I believe this should solve your issue.
CodePudding user response:
You're skipping a step by trying to use open() to fetch a URL: open() can only action files on the local filesystem - https://docs.python.org/3/library/functions.html#open
You'll need to use urllib3/etc. to fetch the file from S3 first (assuming the bucket is also publicly-accessible, as Manish pointed out).
urllib3 usage suggestion: What's the best way to download file using urllib3
So combining the two:
pdf = PdfFileReader(open('S3 FILE URL', 'rb'))
becomes (something like)
import urllib3
def fetch_file(url, save_as):
http = urllib3.PoolManager()
r = http.request('GET', url, preload_content=False)
with open(save_as, 'wb') as out:
while True:
data = r.read(chunk_size)
if not data:
break
out.write(data)
r.release_conn()
if __name__ == "__main__":
pdf_filename = "my_pdf_from_s3.pdf"
fetch_file(s3_file_url, pdf_filename)
pdf = PdfFileReader(open(pdf_filename, 'rb'))