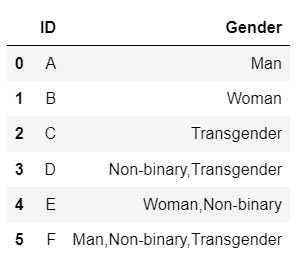
I have a dataframe whose sample is given below.
import pandas as pd
data = {'ID':['A','B','C','D','E','F'],
'Gender':['Man', 'Woman', 'Transgender', 'Non-binary,Transgender', 'Woman,Non-binary',
'Man,Non-binary,Transgender']}
df = pd.DataFrame(data)
df
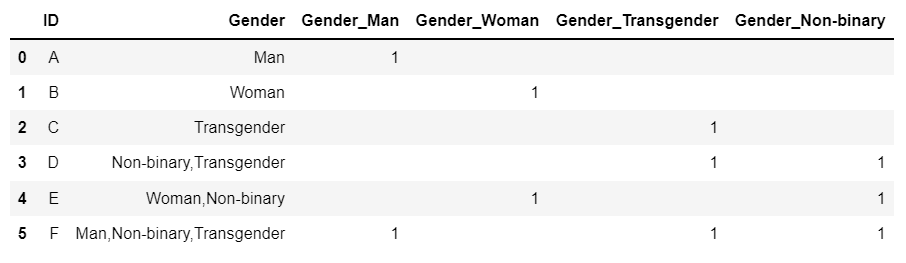
Now, I want to create a column for each value in the 'Gender' column and if the value is present in the row, the new column should have '1' else empty. The final form required is shown below.
Cannot use pd.get_dummies() as there are multiple values(ex: 'Non-binary, Transgender') in many rows. I thought of manually hardcoding for all values, but wanted to know if there is a way to automate the process. Any help is greatly appreciated. Thanks.
CodePudding user response:
Use Series.str.get_dummies, which allows you to specify a separator in the case of multiple values in a string, then join the result back.
pd.concat([df, df['Gender'].str.get_dummies(',').add_prefix('Gender_')], axis=1)
ID Gender Gender_Man Gender_Non-binary Gender_Transgender Gender_Woman
0 A Man 1 0 0 0
1 B Woman 0 0 0 1
2 C Transgender 0 0 1 0
3 D Non-binary,Transgender 0 1 1 0
4 E Woman,Non-binary 0 1 0 1
5 F Man,Non-binary,Transgender 1 1 1 0
CodePudding user response:
Well you can split on , to easily come back to a situation where you can use get_dummies:
>>> df_split = df[['ID']].join(df['Gender'].str.split(',')).explode('Gender')
>>> df_split
ID Gender
0 A Man
1 B Woman
2 C Transgender
3 D Non-binary
3 D Transgender
4 E Woman
4 E Non-binary
5 F Man
5 F Non-binary
5 F Transgender
>>> dummies = pd.get_dummies(df_split['Gender']).groupby(df_split['ID']).max().reset_index()
>>> dummies
ID Man Non-binary Transgender Woman
0 A 1 0 0 0
1 B 0 0 0 1
2 C 0 0 1 0
3 D 0 1 1 0
4 E 0 1 0 1
5 F 1 1 1 0
>>> df.merge(dummies, on='ID')
ID Gender Man Non-binary Transgender Woman
0 A Man 1 0 0 0
1 B Woman 0 0 0 1
2 C Transgender 0 0 1 0
3 D Non-binary,Transgender 0 1 1 0
4 E Woman,Non-binary 0 1 0 1
5 F Man,Non-binary,Transgender 1 1 1 0