lets describe my Problem.
I get a lot of data out of the database. For example it loos like:
d = [
{'Tag': 'Weight', 'Value': 15, 'Product': 'Apple', 'Year': 2019 },
{'Tag': 'Weight', 'Value': 14, 'Product': 'Apple', 'Year': 2020 },
{'Tag': 'Weight', 'Value': 16, 'Product': 'Apple', 'Year': 2021 },
{'Tag': 'Weight', 'Value': 30, 'Product': 'Banana', 'Year': 2019 },
{'Tag': 'Weight', 'Value': 32, 'Product': 'Banana', 'Year': 2020 },
{'Tag': 'Weight', 'Value': 31, 'Product': 'Banana', 'Year': 2021 },
{'Tag': 'Weight', 'Value': 120, 'Product': 'Papaya', 'Year': 2019 },
{'Tag': 'Weight', 'Value': 140, 'Product': 'Papaya', 'Year': 2020 },
{'Tag': 'Weight', 'Value': 130, 'Product': 'Papaya', 'Year': 2021 },
{'Tag': 'Price', 'Value': 0.23, 'Product': 'Apple', 'Year': 2019 },
{'Tag': 'Price', 'Value': 0.23, 'Product': 'Apple', 'Year': 2020 },
{'Tag': 'Price', 'Value': 0.24, 'Product': 'Apple', 'Year': 2021 },
{'Tag': 'Price', 'Value': 0.81, 'Product': 'Banana', 'Year': 2019 },
{'Tag': 'Price', 'Value': 0.83, 'Product': 'Banana', 'Year': 2020 },
{'Tag': 'Price', 'Value': 0.9, 'Product': 'Banana', 'Year': 2021 },
{'Tag': 'Price', 'Value': 2.31, 'Product': 'Papaya', 'Year': 2019 },
{'Tag': 'Price', 'Value': 2.29, 'Product': 'Papaya', 'Year': 2020 },
{'Tag': 'Price', 'Value': 2.41, 'Product': 'Papaya', 'Year': 2021 }
]
I create a dataframe with this command:
df = pd.DataFrame(data = d)
Then the data looks like:
Tag Value Product Year
0 Weight 15.00 Apple 2019
1 Weight 14.00 Apple 2020
2 Weight 16.00 Apple 2021
3 Weight 30.00 Banana 2019
4 Weight 32.00 Banana 2020
5 Weight 31.00 Banana 2021
6 Weight 120.00 Papaya 2019
...
So far so fine. Now I want to sort and filter this dataframe to make nice plots. For example, I want to show the price (Tag == 'Price') of the last years. That means on my X Axis I want to have all of the products and on the y axis I have the corresponsing prices. I want to have for example for each year an individual dataset, labeled with that year. In this example in a bar chart I get 3 bars for each product, each representing the price of a year.
What is the best way of doing it with pandas?
At the moment I am iterating through all of the data, finding the correct ones and filling up new arrays, just to put the newly created arrays into my plots. But that seems not the ideal way.
So question is, how to get my axes for the plots? How yould you solve this problem in a most elegant way? Just with pandas? Possible?
I am excited, thanks a lot
CodePudding user response:
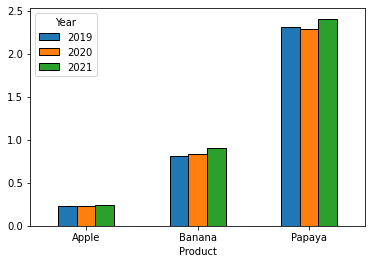
Subset your data to the 'Price' rows, and then reshape with a pivot so the organization is appropriate for the plotting a bar plot -- index is each product and columns for each year.
dfp = (df[df['Tag'].eq('Price')]
.pivot(index='Product', columns='Year', values='Value'))
#Year 2019 2020 2021
#Product
#Apple 0.23 0.23 0.24
#Banana 0.81 0.83 0.90
#Papaya 2.31 2.29 2.41
dfp.plot(kind='bar', rot=0, ec='k')
CodePudding user response:
Try this:
import numpy as np
import matplotlib.pyplot as plt
# set width of bar
barWidth = 0.25
fig = plt.subplots(figsize =(12, 8))
# set height of bar
Apple = list(df[(df.Product=='Apple')&(df.Tag=='Price')].Value)
Banana = list(df[(df.Product=='Banana')&(df.Tag=='Price')].Value)
Papaya = list(df[(df.Product=='Papaya')&(df.Tag=='Price')].Value)
# Set position of bar on X axis
br1 = np.arange(len(Apple))
br2 = [x barWidth for x in br1]
br3 = [x barWidth for x in br2]
# Make the plot
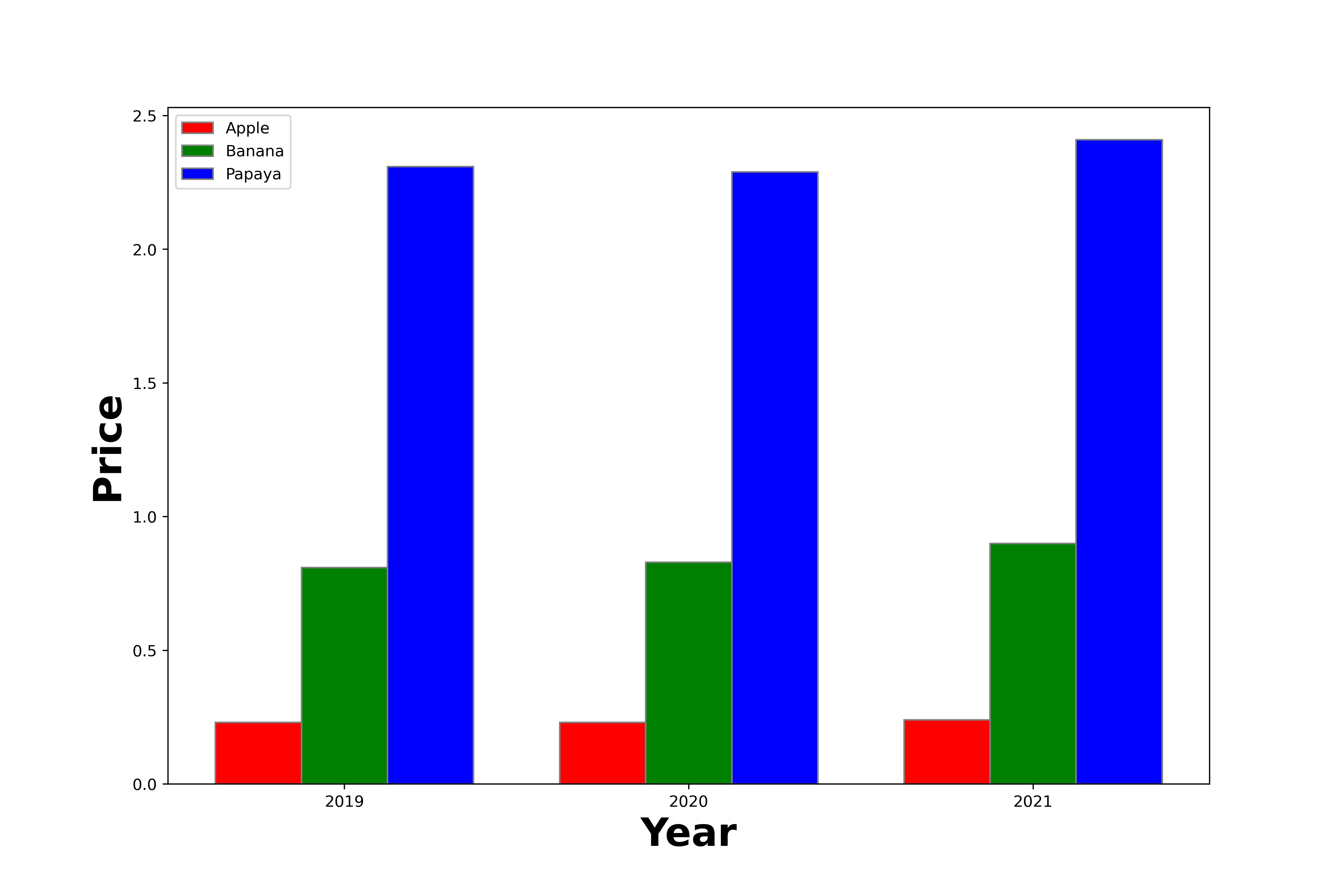
plt.bar(br1, Apple, color ='r', width = barWidth,
edgecolor ='grey', label ='Apple')
plt.bar(br2, Banana, color ='g', width = barWidth,
edgecolor ='grey', label ='Banana')
plt.bar(br3, Papaya, color ='b', width = barWidth,
edgecolor ='grey', label ='Papaya')
# Adding Xticks
plt.xlabel('Year', fontweight ='bold', fontsize = 25)
plt.ylabel('Price', fontweight ='bold', fontsize = 25)
plt.xticks([r barWidth for r in range(len(Apple))],['2019','2020','2021'])
plt.legend()
plt.show()
Output: