I have a dataframe that look like this:
| HR | O2Sat | Temp | DBP | Resp | P_ID |
|---|---|---|---|---|---|
| 96 | 99.2 | 36.50 | 60.0 | 10.0 | 1 |
| 95 | 100.0 | 39.50 | 68.5 | 12.0 | 1 |
| 110 | 85.8 | 37.95 | 58.5 | 19.2 | 2 |
| 100 | 95.5 | 35.45 | 45.9 | 11.5 | 2 |
| 89 | 98.0 | 38.10 | 65.4 | 10.5 | 3 |
| 98 | 100.0 | 36.50 | 49.5 | 15.8 | 3 |
| 102 | 100.0 | 37.45 | 60.0 | 16.0 | 4 |
| 115 | 95.0 | 38.05 | 55.8 | 14.5 | 4 |
I want to have the 1st two rows (P_ID = 1) under single ID (ID = 1), and so on. So that when I do analysis on basis of patient ID, it will consider all rows having that ID as a group, instead of dealing them as separate rows. Like this:
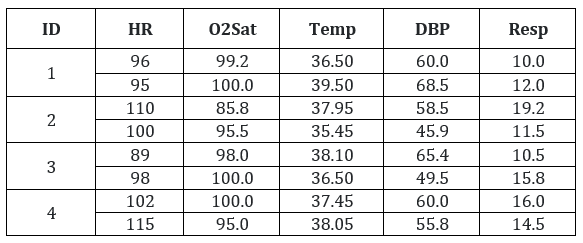
How I can do that? Please help.
Update:
This will be my desired output of my dataframe. This is the time-series data from PhysioNet Sepsis Challenge 2019. I considered every row as a separate patient. But this is not good approach. I want to do my analysis patient wise no matter how many entries (rows) that patient has. Not considering individual row as a separate patient, but the individual row as a data of that patient having unique ID.
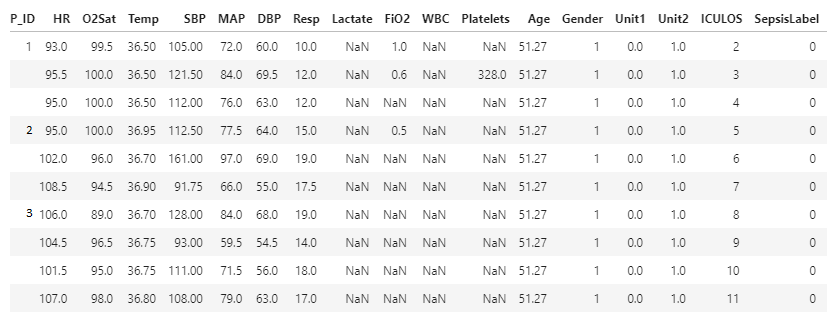
CodePudding user response:
Let's imagine the following DataFrame:
col1 col2
0 A 1
1 A 2
2 A 3
3 B 4
4 B 5
5 C 6
6 C 7
7 D 8
You can mask the duplicated keys:
df['col1'] = df.mask(df['col1'].duplicated(), '')
output:
col1 col2
0 A 1
1 2
2 3
3 B 4
4 5
5 C 6
6 7
7 D 8
NB. be aware that the content of the dataframe changes, now you cannot use the value A in row 2 for instance
CodePudding user response:
You can try:
df.loc[df['P_ID'].eq(df['P_ID'].shift()), 'P_ID'] = ''
df = df.set_index('P_ID').reset_index()
Output:
>>> df
P_ID HR O2Sat Temp DBP Resp
0 1 96 99.2 36.50 60.0 10.0
1 95 100.0 39.50 68.5 12.0
2 2 110 85.8 37.95 58.5 19.2
3 100 95.5 35.45 45.9 11.5
4 3 89 98.0 38.10 65.4 10.5
5 98 100.0 36.50 49.5 15.8
6 4 102 100.0 37.45 60.0 16.0
7 115 95.0 38.05 55.8 14.5