I have the first excel file user_details.csv
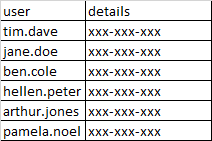
I have another excel file user_mangers.csv
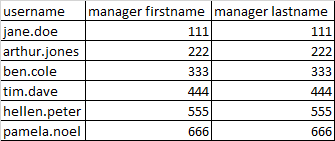
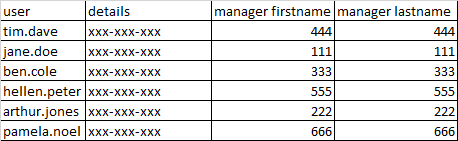
I need to loop and select each of the users from user_details.csv one by one, find the corresponding manager from user_managers.csv and append the details into a new csv file, say user_details_managers.csv like below.
CodePudding user response:
Can be easily done with pandas:
import pandas as pd
user_details = pd.read_csv('user_details.csv')
user_managers = pd.read_csv('user_mangers.csv')
merged_df = user_details.merge(user_managers, how='left', left_on='user', right_on='username')
merged_df.to_csv('user_details_managers.csv')
So what happens here? I used pandas to read both csv files into dataframes. Then we merged them into a single dataframe: on the "left" dataframe (here is user_details) we merged on "user" column, and on the "right" dataframe (user_mangers) it took the "username" column. It mean it will combine each "user" from the left with "username" from the right.
The result is a single dataframe, and I use .to_csv() to save it back as csv.
P.S - Please review how to ask guide, as your question is missing what you tried - StackOverflow community is not here to write code for you but to help you. Although I answered your question (cause it's quick), usually the community will not help you if your question doesn't meet the minimum standard.
CodePudding user response:
In case you wanted to have less dependencies, this is how you do it with the standard csv library:
import csv
# collect the corresponding items by username
user_details_managers = {}
with open("./user_details.csv") as details_fp:
reader = csv.reader(details_fp)
# read first row to skip headers
next(reader)
for row in reader:
user, details = row
user_details_managers[user] = [user, details]
with open("./user_managers.csv") as managers_fp:
reader = csv.reader(managers_fp)
# read first row to skip headers
next(reader)
for row in reader:
username, firstname, lastname = row
if username in user_details_managers:
user_details_managers[username].extend([firstname, lastname])
with open("./user_details_managers.csv", "w") as details_managers_fp:
writer = csv.writer(details_managers_fp)
# write headers
writer.writerow(["user", "details", "manager firstname", "manager lastname"])
# write combined rows
writer.writerows(user_details_managers.values())