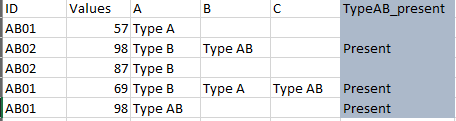
I have a df with columns ID, Value, A,B,C. I want to check if a string, say "Type AB", is in any row of the columns A, B, C. If its present, I want to mark that it "Present" for that row in the new column "TypeAB_present". How do I achieve this in python?
CodePudding user response:
Try with np.where with any
df['TypeAB _present'] = np.where(df[['A', 'B', 'C']].eq('Type AB').any(axis = 1 ), 'Present', '')
CodePudding user response:
Assuming you're using pandas and you're looking for the exact 'Type AB' tag from any of the columns.
df['TypeAB_present'] = df[['A', 'B', 'C']].apply(lambda row: 'Present' if 'Type AB' in row.values else '', axis=1)
CodePudding user response:
You can try this:
import pandas as pd
df = pd.DataFrame(
{
'ID': ['AB01', 'AB02', 'AB02', 'AB01', 'AB01'],
'Values': [57, 98, 87, 69, 98],
'A': ['Type A', 'Type B', 'Type B', 'Type B', 'Type AB'],
'B': [None, 'Type AB', None, 'Type A', None]
}
)
df.loc[(df[['A', 'B']] == 'Type AB').any(axis=1), 'C'] = 'Present'
df
Out
ID Values A B C
0 AB01 57 Type A None NaN
1 AB02 98 Type B Type AB Present
2 AB02 87 Type B None NaN
3 AB01 69 Type B Type A NaN
4 AB01 98 Type AB None Present
If your check is slightly more complicated than exact equality match, you can create a more robust mask for indexing. Here I'm checking to see if any of the strings in columns A or B contain the substring 'AB':
match_mask = df[['A', 'B']].apply(lambda x: x.str.contains('AB')).any(axis=1)
df.loc[match_mask, 'C'] = 'Present'