I have encountered issues with dask which I cannot see in Pandas. I have read small dataset in a notebook in google cloud.
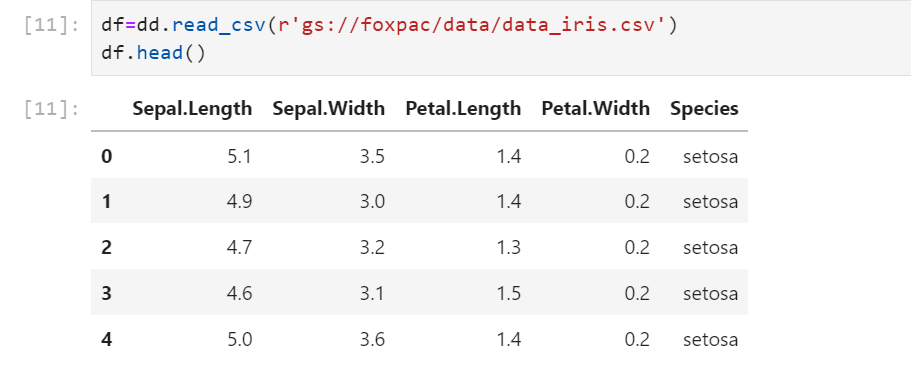
df is saved as a dataframe and I now remove the source 'data_iris.csv' file and it shows filenotfound error.
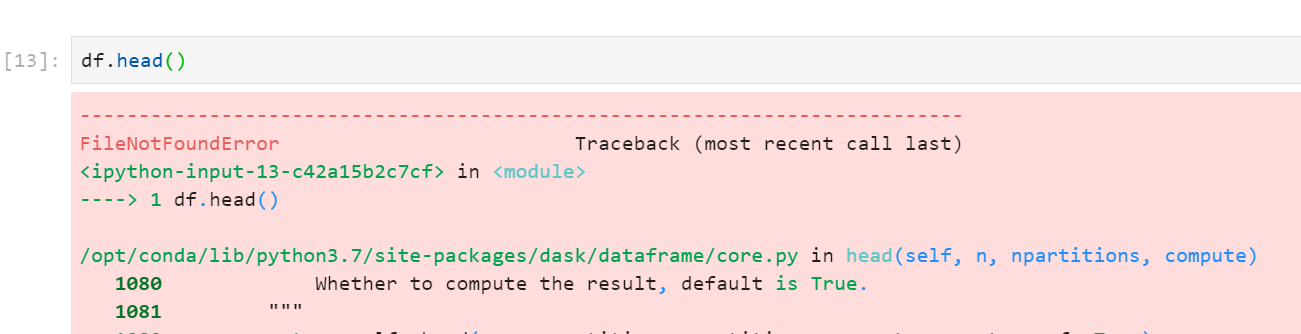 How to overcome from it since I want to delete the file after saving into dataframe.
How to overcome from it since I want to delete the file after saving into dataframe.
CodePudding user response:
Dask specialises in managing data sets that are bigger that your system's memory (and possibly computing in parallel across a cluster). It's operations are chunk-wise and lazy - things don't happen until you explicitly ask, and are not held in memory.
df is saved as a dataframe
It is not. You have merely made a prescription for how to load that dataframe.
If you want to hold the data in memory, you could do
df = df.persist() # hold in dask worker memory
or
df = df.compute() # convert to Pandas
If you can do these things safely, then probably the data is too small for you to have bothered using Dask in the first place.
CodePudding user response:
Dask works by providing access to a file on a disk. It is not designed to keep all the files/data into a memory that's why it is powerful than pandas for handling large data.
This is why it handles data larger than RAM as a single dataframe.