This is my query sample:
IF OBJECT_ID('tempdb..##A') IS NOT NULL DROP TABLE ##A
IF OBJECT_ID('tempdb..#table1') IS NOT NULL DROP TABLE #table1
Create table #Table1 ( ControlNo INT, Line varchar(50), Profit INT, Code varchar(50) )
INSERT INTO #Table1 (ControlNo, Line, Profit, Code)
VALUES (1111,'Line1',NULL,NULL),
(1111,'Line2',100,'A'),
(3333,'Line1',200,'C'),
(4444,'Line1',50,'B'),
(4444,'Line2',100,NULL)
DECLARE @columns AS NVARCHAR(MAX),
@finalquery AS NVARCHAR(MAX);
SET @columns = STUFF((SELECT distinct ',' QUOTENAME(Line) FROM #Table1 FOR XML PATH(''), TYPE ).value('.', 'NVARCHAR(MAX)') ,1,1,'')
set @finalquery = '
select p.ControlNo,
p.Code,' @columns '
from ( select ControlNo, Line, Code, Profit
from #Table1
)a
pivot
(
SUM(Profit)
for Line IN (' @columns ')
)p
ORDER BY ControlNo
'
exec(@finalquery)
Outcome has rows with NULL's in it.
ControlNo Code Line1 Line2
1111 NULL NULL NULL
1111 A NULL 100
3333 C 200 NULL
4444 NULL NULL 100
4444 B 50 NULL
The desired output needs to be like this:
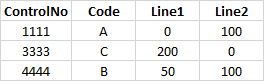
CodePudding user response:
Just apply coalesce null to '0' in your subquery then group by is not needed.
IF OBJECT_ID('tempdb..##A') IS NOT NULL DROP TABLE ##A
IF OBJECT_ID('tempdb..#table1') IS NOT NULL DROP TABLE #table1
Create table #Table1 ( ControlNo INT, Line varchar(50), Profit INT,
Code varchar(50) )
INSERT INTO #Table1 (ControlNo, Line, Profit, Code)
VALUES (1111,'Line1',NULL,NULL),
(1111,'Line2',100,'A'),
(3333,'Line1',200,'C'),
(4444,'Line1',50,'B'),
(4444,'Line2',100,NULL)
DECLARE @columns AS NVARCHAR(MAX),
@finalquery AS NVARCHAR(MAX);
SET @columns = STUFF((SELECT distinct ',' QUOTENAME(Line)
FROM #Table1 FOR XML PATH(''), TYPE ).value('.', 'NVARCHAR(MAX)') ,1,1,'')
set @finalquery = '
select p.ControlNo,
p.Code,' @columns '
from ( select distinct ControlNo, coalesce(Line,'0')as Line,
coalesce(Code,'0') as Code, coalesce(Profit,'0')as Profit
from #Table1
)a
pivot
(
SUM(Profit)
for Line IN (' @columns ')
)p
ORDER BY ControlNo
'
exec(@finalquery)
CodePudding user response:
It looks like regular conditional aggregation would work better here, because Code appears to be just MIN(Code) per ControlNo
DECLARE @columns nvarchar(max) =
STUFF((SELECT distinct
',ISNULL(SUM(CASE WHEN Line = ' QUOTENAME(Line, '''') ' THEN Profit END), 0) ' QUOTENAME(Line)
FROM #Table1
FOR XML PATH(''), TYPE
).value('text()[1]', 'NVARCHAR(MAX)') ,1 , LEN(','),'');
DECLARE @finalquery nvarchar(max)= N'
SELECT
t.ControlNo,
MIN(t.Code) Code,
' @columns '
from #Table1 t
GROUP BY
t.ControlNo
ORDER BY ControlNo;
';
PRINT @finalquery; -- for testing
EXEC sp_executesql
@finalquery;