I have jsut started to use databricks, I'm using the community cloud and I'm trying to read json file. I have tried to do this as following:
from pyspark.sql import SparkSession
df=spark.read.json('people')
But then I'm getting error:
IllegalArgumentException: Path must be absolute: people
I have tried to acess the people.json file with different writing:
'people.json', '/people.json','Data/deafult/people' ect., the last one is based on where I understood that the data is stored:
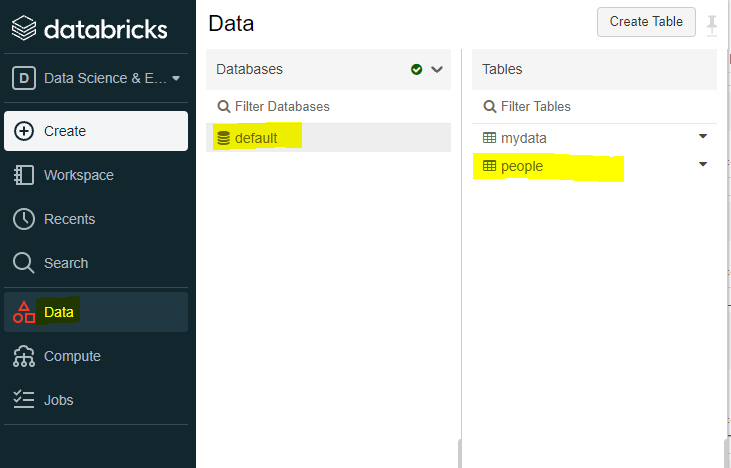
However, that did not work and I kept geting the same error message.
HoWhenever I try to read it with sql.Context.sql it shows the table:
df=sqlContext.sql("SELECT * FROM people")
df.show()
>>>
---- -------
| age| name|
---- -------
|null|Michael|
| 30| Andy|
| 19| Justin|
---- -------
So my question is how can I open the json file with spark.read.json?
CodePudding user response:
why do you want to use spark.read.json?
In you picture, "people" is clearly a table.
If you want to read a table in spark, you do : spark.table("people").
You use spark.read.json when you want to read a json file. In that case you do : spark.read.json("absolute/path/to/json/file") but you need to know that path (and that's exactly the error you've got). I have no idea where your files are stored, that's entirely on you to know it. Where did you put them ?