I have ticks data of 2 scrips (scrip_names are abc and xyz). Since the ticks data is at a "second" level, I want to convert this to OHLC (Open, High, Low, Close) at 1 Minute level.
When the ticks data contains only 1 scrip, I use the following code (OHLC of Single Scrip.py) to get the OHLC at 1 Minute level. This code gives the desired result.
Code:
import os
import time
import datetime
import pandas as pd
import numpy as np
ticks=pd.read_csv(r'C:\Users\tech\Downloads\ticks.csv')
ticks=pd.DataFrame(ticks)
#ticks=ticks.where(ticks['scrip_name']=="abc")
#ticks=ticks.where(ticks['scrip_name']=="xyz")
ticks['timestamp'] = pd.to_datetime(ticks['timestamp'])
ticks=ticks.set_index(['timestamp'])
ohlc_prep=ticks.loc[:,['last_price']]
ohlc_1_min=ohlc_prep['last_price'].resample('1min').ohlc().dropna()
ohlc_1_min.to_csv(r'C:\Users\tech\Downloads\ohlc_1_min.csv')
Result:
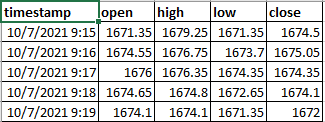
However, when the ticks data contains more than 1 scrip, this code doesn't work. What modifications should be done to the code to get the following result (filename: expected_result.csv) which is grouped by scrip_name.
Expected Result:
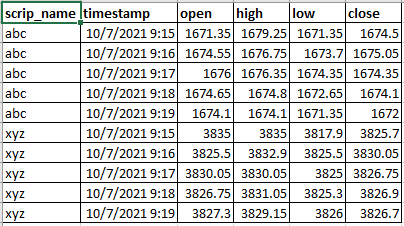
Here is the link to ticks data, python code for single scrip, result of single scrip, and desired result of multiple scrips: https://drive.google.com/file/d/1Y3jngm94hqAW_IJm-FAsl3SArVhnjGJE/view?usp=sharing
Any help is much appreciated.
thank you.
CodePudding user response:
I think you need groupby like:
ticks['timestamp'] = pd.to_datetime(ticks['timestamp'])
ticks=ticks.set_index(['timestamp'])
ohlc_1_min=ticks.groupby('scrip_name')['last_price'].resample('1min').ohlc().dropna()
Or:
ohlc_1_min=(ticks.groupby(['scrip_name',
pd.Grouper(freq='1min', level='timestamp')])['last_price']
.ohlc()
.dropna())