I am trying to create a dataframe out the XML code as shown below
<Structure>
<Field>
<Field_Name>GAMEREF</Field_Name>
<Field_Type>Numeric</Field_Type>
<Field_Len>4</Field_Len>
<Field_Dec>0</Field_Dec>
</Field>
...
<Field>
<Field_Name>WINLOSS</Field_Name>
<Field_Type>Character</Field_Type>
<Field_Len>1</Field_Len>
<Field_Dec>0</Field_Dec>
</Field>
</Structure>
<Records>
<Record>
<GAMEREF>1217</GAMEREF>
<YEAR>2021</YEAR>
(MORE ELEMENTS I DO NOT CARE ABOUT)
<GAMENO>1</GAMENO>
<WINLOSS>W</WINLOSS>
</Record>
...
<Record>
<GAMEREF>1220</GAMEREF>
<YEAR>2021</YEAR>
(MORE ELEMENTS I DO NOT CARE ABOUT)
<GAMENO>4</GAMENO>
<WINLOSS>L</WINLOSS>
</Record>
</Records>
The structure section of the XML code that is irrelevant to the dataframe I am trying to create.
I am trying to only use the XML elements of GAMEREF, YEAR, GAMENO, and WINLOSS as there are more in the XML for the Record elements.
I have tried using code as shown below to get this to work, but when I run the code I get the error of "AttributeError: 'NoneType' object has no attribute 'text'"
Code is below.
import pandas as pd
import xml.etree.ElementTree as et
xtree = et.parse("gamedata.xml")
xroot = xtree.getroot()
df_cols = ["GAME REF","YEAR", "GAME NO", "WIN LOSS"]
rows = []
for child in xroot.iter():
s_gameref = child.find('GAMEREF').text,
s_year = child.find('YEAR').text,
s_game_no = child.find('GAMENO').text,
s_winloss = child.find('WINLOSS').text
rows.append({"GAME REF": s_gameref,"YEAR": s_year,
"GAME NO": s_game_no, "WIN LOSS": s_winloss})
df = pd.DataFrame(rows, columns = df_cols)
The code is based off other stuff I have seen on the Stack and other sites, but nothing is working yet.
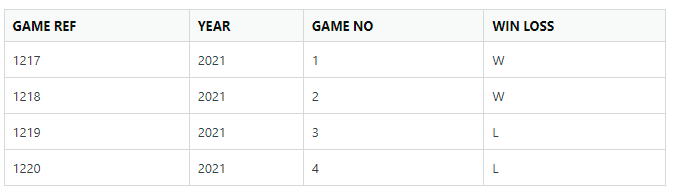
Ideal dataframe output is below
| GAME REF | YEAR | GAME NO | WIN LOSS |
|---|---|---|---|
| 1217 | 2021 | 1 | W |
| 1218 | 2021 | 2 | W |
| 1219 | 2021 | 3 | L |
| 1220 | 2021 | 4 | L |
Thanks
EDIT - NOT SURE WHAT IS GOING ON WITH MY TABLE, BUT IT SHOULD LOOK LIKE THIS
CodePudding user response:
I think the below is what you are looking for. (Just loop over the "interesting" sub elements of Record). The logic of the code is in the line that starts with data = [.... The 2 loops can be found there.
import pandas as pd
import xml.etree.ElementTree as ET
xml = '''<r><Structure>
<Field>
<Field_Name>GAMEREF</Field_Name>
<Field_Type>Numeric</Field_Type>
<Field_Len>4</Field_Len>
<Field_Dec>0</Field_Dec>
</Field>
...
<Field>
<Field_Name>WINLOSS</Field_Name>
<Field_Type>Character</Field_Type>
<Field_Len>1</Field_Len>
<Field_Dec>0</Field_Dec>
</Field>
</Structure>
<Records>
<Record>
<GAMEREF>1217</GAMEREF>
<YEAR>2021</YEAR>
<GAMENO>1</GAMENO>
<WINLOSS>W</WINLOSS>
</Record>
<Record>
<GAMEREF>1220</GAMEREF>
<YEAR>2021</YEAR>
<GAMENO>4</GAMENO>
<WINLOSS>L</WINLOSS>
</Record>
</Records></r>'''
fields = {'GAMEREF':'GAME REF', 'YEAR':'YEAR', 'GAMENO':'GAME NO','WINLOSS':'WIN LOSS'}
root = ET.fromstring(xml)
data = [{display_name: rec.find(element_name).text for element_name,display_name in fields.items()} for rec in root.findall('.//Record')]
df = pd.DataFrame(data)
print(df)
output
GAME REF YEAR GAME NO WIN LOSS
0 1217 2021 1 W
1 1220 2021 4 L
CodePudding user response:
import pandas as pd
import xml.etree.ElementTree as et
xtree = et.parse("gamedata.xml")
xroot = xtree.getroot()
df_cols = ["GAME REF","YEAR", "GAME NO", "WIN LOSS"]
rows = []
for record in xroot:
s_gameref = record.find('GAMEREF').text
s_year = record.find('YEAR').text
s_game_no = record.find('GAMENO').text
s_winloss = record.find('WINLOSS').text
rows.append({"GAME REF": s_gameref,"YEAR": s_year,
"GAME NO": s_game_no, "WIN LOSS": s_winloss})
df = pd.DataFrame(rows, columns = df_cols)
Remove .iter()