There are 3 sets of dataframe code below:
dataset = {
'X1': [18, 70, 70, 65, 18],
'X2': [1, 2, 2, 2, 1],
'X3': [45, 55, 22, 31, 23],
'X4': [1, 2, 1, 1, 2],
'X5': [65, 80, 500, 200, 100]}
df = pd.DataFrame(dataset)
dataset1 = {
'Variable': ['X1', 'X2', 'X3', 'X4', 'X5'],
'Label': ['Age', 'Sex', 'Ethnicity', 'Education', 'Income']}
df_labels = pd.DataFrame(dataset1)
dataset2 = {
'Variable': ['X1', 'X1', 'X1', 'X4', 'X4', 'X2', 'X2', 'X5', 'X5'],
'Code': [18, 70, 65, 1, 2, 1, 2, 65, 80],
'Value': ['18-24', '70-90', '65-80', 'Degree', 'Masters', 'Male', 'Female', '65K', '80K'] }
df_values = pd.DataFrame(dataset2)
df
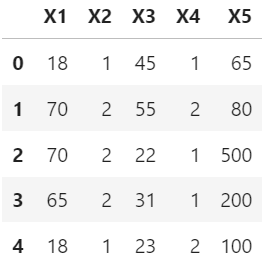
df_labels
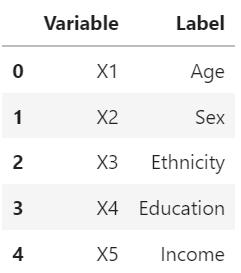
df_values
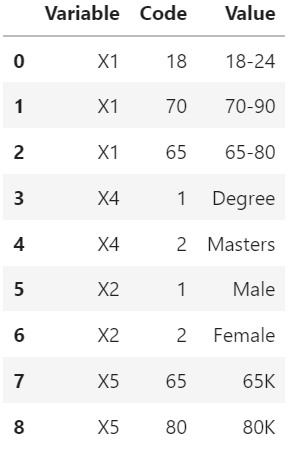
I wrote the following code to replace the values in the df dataframe, using the df_values table.
df["X1"].replace({18: "18-24", 70: "70-90", 65: "65-80"}, inplace=True)
df["X2"].replace({1: "Male", 2: "Female"}, inplace=True)
df["X4"].replace({1: "Degree", 2: "Masters"}, inplace=True)
df["X5"].replace({65: "65K", 80: "80K"}, inplace=True)
This resulted in this dataframe:
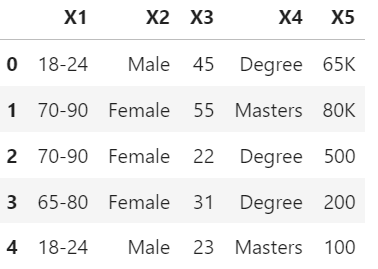
This replacement was simple because there is only 4 sets of replacements to a few variables. However, the dataset contains nearly 100 variables. Is there an easier method to replace all the values (for all 100 variables) using the df_values table ?
CodePudding user response:
Let us try replace after pivoting the replacement dataframe
df.replace(df_values.pivot(*df_values).T)
X1 X2 X3 X4 X5
0 18-24 Male 45 Degree 65K
1 70-90 Female 55 Masters 80K
2 70-90 Female 22 Degree 500
3 65-80 Female 31 Degree 200
4 18-24 Male 23 Masters 100
CodePudding user response:
Idea is create nested dictionary by columns names and then use DataFrame.replace:
d = (df_values.groupby('Variable')
.apply(lambda x: x.set_index('Code')['Value'].to_dict())
.to_dict())
df = df.replace(d)
print (df)
X1 X2 X3 X4 X5
0 18-24 Male 45 Degree 65K
1 70-90 Female 55 Masters 80K
2 70-90 Female 22 Degree 500
3 65-80 Female 31 Degree 200
4 18-24 Male 23 Masters 100