From my original data frame, I used the group-by to create the new df as shown below, which has the natural disaster subtype counts for each country.
However, I'm unsure how to, for example, select 4 specific countries and set them as variables in a 2 by 2 plot.
The X-axis will be the disaster subtype name, with the Y being the value count, however, I can't quite figure out the right code to select this information.
This is how I grouped the countries -
g_grp= df_geo.groupby(['Country'])
c_val = pd.DataFrame(c_grp['Disaster Subtype'].value_counts())
c_val = c_val.rename(columns={'Disaster Subtype': 'Disaster Subtype', 'Disaster Subtype': 'Num of Disaster'})
c_val.head(40)
Output:
Country Disaster Subtype
Afghanistan Riverine flood 45
Ground movement 33
Flash flood 32
Avalanche 19
Drought 8
Bacterial disease 7
Convective storm 6
Landslide 6
Cold wave 5
Viral disease 5
Mudslide 3
Severe winter conditions 2
Forest fire 1
Locust 1
Parasitic disease 1
Albania Ground movement 16
Riverine flood 8
Severe winter conditions 3
Convective storm 2
Flash flood 2
Heat wave 2
Avalanche 1
Coastal flood 1
Drought 1
Forest fire 1
Viral disease 1
Algeria Ground movement 21
Riverine flood 20
Flash flood 8
Bacterial disease 2
Cold wave 2
Forest fire 2
Coastal flood 1
Drought 1
Heat wave 1
Landslide 1
Locust 1
American Samoa Tropical cyclone 4
Flash flood 1
Tsunami 1
However, let's say I want to select these for and plot 4 plots, 1 for each country, showing the number of each type of disaster happening in each country, I know I would need something along the lines of what's below, but I'm unsure how to set the x and y variables for each -- or if there is a more efficient way to set the variables/plot, that would be great. Usually, I would just use loc or iloc, but I need to be more specific with selecting.
fig, ax = subplots(2,2, figsize(16,10)
X1 = c_val.loc['Country'] == 'Afghanistan' #This doesn't work, just need something similar
y1 = c_val.loc['Num of Disasters']
X2 =
y2 =
X3 =
y3 =
X4 =
y4 =
ax[0,0].bar(X1,y1,width=.4, color=['#A2BDF2'])
ax[0,1].bar(X2,y2,width=.4,color=['#A2BDF2'])
ax[1,0].bar(X3,y3,width=.4,color=['#A2BDF2'])
ax[1,1].bar(X4,y4,width=.4,color=['#A2BDF2'])
CodePudding user response:
IIUC, an simple way is to use 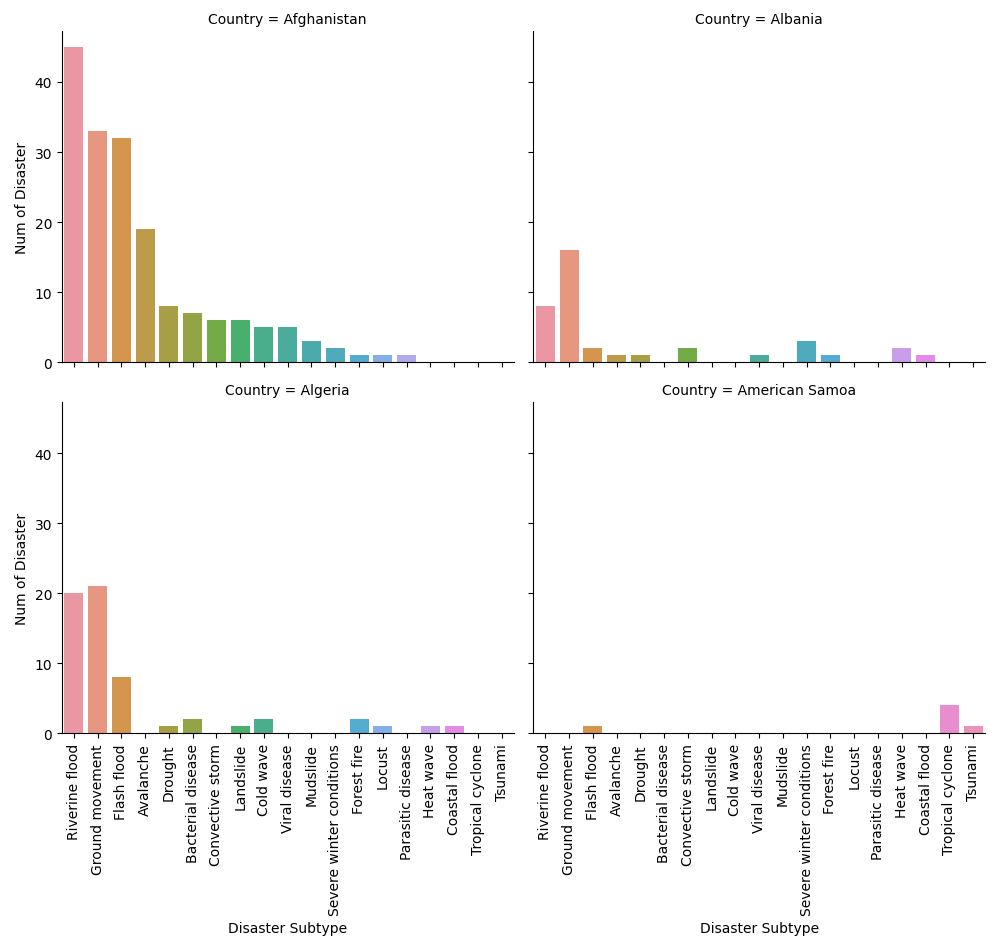
Update
How I can select the specific countries to be plotted in each subplot?
subdf = df.loc[df['Country'].isin(['Albania', 'Algeria'])]
g = sns.catplot(x='Disaster Subtype', y='Num of Disaster', col='Country',
data=subdf, col_wrap=2, kind='bar')
...