I would like to calculate the standard deviation for each column in the data frame, but only for the selected rows. I would like to reflect this formula from Excel (calculates standard deviation only for highlighted cells and moves one index down each column)
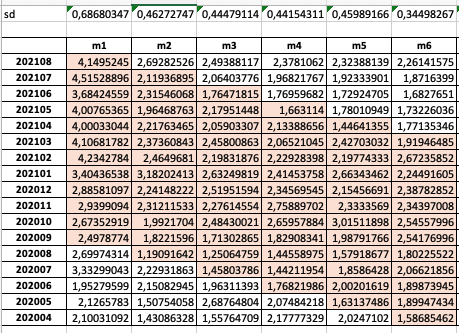
Could you please advise me how should I construct my loop to do that? Thank you.
CodePudding user response:
I would use numpy for that:
example input:
>>> df = pd.DataFrame(np.arange(50).reshape(10,5,order='F')).add_prefix('m')
>>> df
m0 m1 m2 m3 m4
0 0 10 20 30 40
1 1 11 21 31 41
2 2 12 22 32 42
3 3 13 23 33 43
4 4 14 24 34 44
5 5 15 25 35 45
6 6 16 26 36 46
7 7 17 27 37 47
8 8 18 28 38 48
9 9 19 29 39 49
output (here using 5 rows):
>>> pd.Series(np.c_[[np.diagonal(df.values, offset=-i) for i in range(5)]].std(axis=0), index=df.columns)
m0 1.414214
m1 1.414214
m2 1.414214
m3 1.414214
m4 1.414214
This works by creating an intermediary array:
>>> np.c_[[np.diagonal(df.values, offset=-i) for i in range(5)]]
array([[ 0, 11, 22, 33, 44],
[ 1, 12, 23, 34, 45],
[ 2, 13, 24, 35, 46],
[ 3, 14, 25, 36, 47],
[ 4, 15, 26, 37, 48]])
imports:
import pandas as pd
import numpy as np