I'm starting with SQL and doing some exercises and I'm completely stuck on the last one. It is about looking for streets in the same country name. Two tables are used, locations and countries from the HR schema. The problem is that I don't know how to avoid duplicate results. For example if I have the street "x" in Canada and the street "y" also in Canada, it shows me twice:
- street x / Canada / street y
- street y / Canada / street x and I can't find a way to correct this.
My select is:
SELECT DISTINCT A.STREET_ADDRESS AS "CALLE A", C.COUNTRY_NAME, B.STREET_ADDRESS AS "CALLE B"
FROM HR.LOCATIONS A JOIN HR.LOCATIONS B ON (A.STREET_ADDRESS <> B.STREET_ADDRESS), HR.COUNTRIES C
WHERE A.COUNTRY_ID = B.COUNTRY_ID AND B.COUNTRY_ID = C.COUNTRY_ID
ORDER BY C.COUNTRY_NAME
I get this Result_
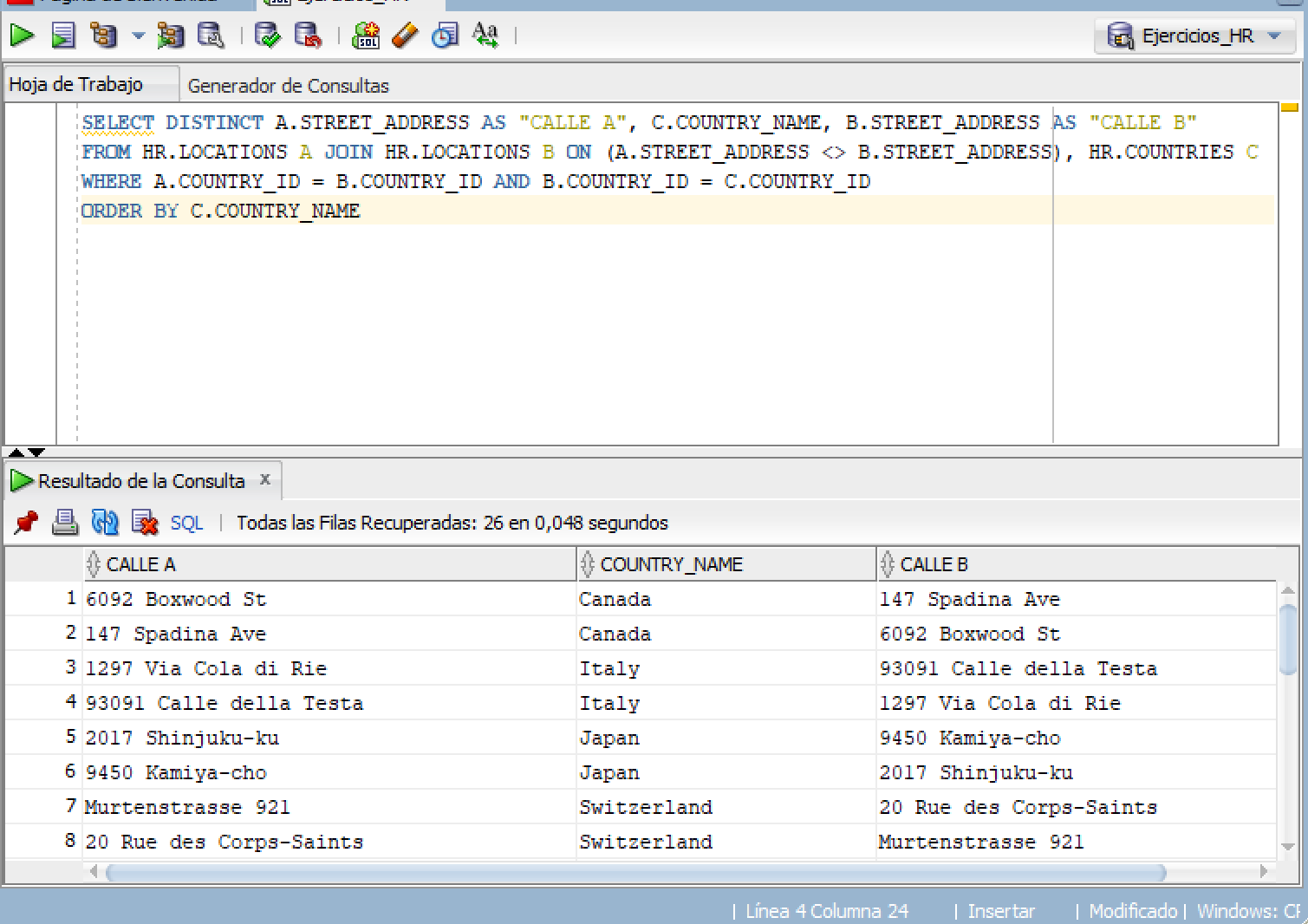
Any ideas? Thank you.
CodePudding user response:
use < instead of <>
SELECT DISTINCT A.STREET_ADDRESS AS "CALLE A", C.COUNTRY_NAME, B.STREET_ADDRESS AS "CALLE B"
FROM HR.LOCATIONS A JOIN HR.LOCATIONS B ON (A.STREET_ADDRESS > B.STREET_ADDRESS), HR.COUNTRIES C
WHERE A.COUNTRY_ID = B.COUNTRY_ID AND B.COUNTRY_ID = C.COUNTRY_ID
ORDER BY C.COUNTRY_NAME
CodePudding user response:
All the correct answers should be logically equivalent. You may want to use a form closer to this, however.
Ignore the alignment, unless you feel it helps readability (I happen to).
I'm referring more to the JOIN / ON form (avoid comma separated table expressions in the FROM clause, called <table reference list> ... a single <table reference> is usually sufficient), as @jarlh mentioned, and to keep the join criteria (in the ON clauses) nearer to the corresponding tables in the FROM clause, unless you have a particular reason to separate any of the logic to the WHERE clause (try to avoid that, unless necessary).
Logically, we can write these in lots of different ways. Some may be a little easier to write/read.
SELECT A.STREET_ADDRESS AS "CALLE A"
, C.COUNTRY_NAME
, B.STREET_ADDRESS AS "CALLE B"
FROM HR.LOCATIONS A
JOIN HR.LOCATIONS B
ON A.COUNTRY_ID = B.COUNTRY_ID
AND A.STREET_ADDRESS < B.STREET_ADDRESS
JOIN HR.COUNTRIES C
ON B.COUNTRY_ID = C.COUNTRY_ID
ORDER BY C.COUNTRY_NAME
;
The inequality, as @nbk points out, avoids the street reflections.
SELECT DISTINCT isn't really needed for this, if your join logic and selected detail is sufficient to identify unique locations. If not, the result probably isn't practically useful.
If this is a small subset of sample data and/or these street addresses are unique within each country, then you're also ok, and DISTINCT isn't needed.