I need to efficiently fuzzy-join two huge tables.
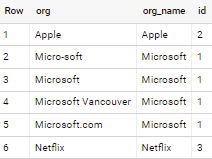
Sample data:
WITH orgs AS (
(SELECT 'Microsoft' AS org)
UNION ALL
(SELECT 'Micro-soft' AS org)
UNION ALL
(SELECT 'Microsoft.com' AS org)
UNION ALL
(SELECT '@microsoft' AS org)
UNION ALL
(SELECT 'Microsoft Vancouver' AS org)
UNION ALL
(SELECT 'Apple' AS org)
UNION ALL
(SELECT 'Netflix' AS org)
),
orgs_ids AS (
(SELECT 'Microsoft' AS org_name, '1' AS id)
UNION ALL
(SELECT 'Apple' AS org_name, '2' AS id)
UNION ALL
(SELECT 'Netflix' AS org_name, '3' AS id)
)
...
Expected result:
--------------------- ----------- ---
| Microsoft | Microsoft | 1 |
--------------------- ----------- ---
| Micro-soft | Microsoft | 1 |
--------------------- ----------- ---
| Microsoft.com | Microsoft | 1 |
--------------------- ----------- ---
| @microsoft | Microsoft | 1 |
--------------------- ----------- ---
| Microsoft Vancouver | Microsoft | 1 |
--------------------- ----------- ---
| Apple | Apple | 2 |
--------------------- ----------- ---
| Netflix | Netflix | 3 |
--------------------- ----------- ---
This query does the job:
WITH orgs AS (
(SELECT 'Microsoft' AS org)
UNION ALL
(SELECT 'Micro-soft' AS org)
UNION ALL
(SELECT 'Microsoft.com' AS org)
UNION ALL
(SELECT '@microsoft' AS org)
UNION ALL
(SELECT 'Microsoft Vancouver' AS org)
UNION ALL
(SELECT 'Apple' AS org)
UNION ALL
(SELECT 'Netflix' AS org)
),
orgs_ids AS (
(SELECT 'Microsoft' AS org_name, '1' AS id)
UNION ALL
(SELECT 'Apple' AS org_name, '2' AS id)
UNION ALL
(SELECT 'Netflix' AS org_name, '3' AS id)
),
orgs_match AS (
SELECT
org,
(fhoffa.x.levenshtein(org, org_name)) AS match,
org_name,
id
FROM orgs
JOIN orgs_ids ON TRUE
)
SELECT DISTINCT
org,
FIRST_VALUE(org_name) OVER (PARTITION BY(org) ORDER BY match ASC) as org_name,
FIRST_VALUE(id) OVER (PARTITION BY(org) ORDER BY match ASC) as id
FROM orgs_match
But as far as I understand, this is extremely inefficient. Is there a better way?
CodePudding user response:
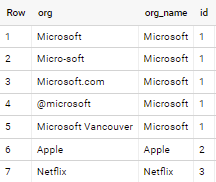
Consider below approach
select org,
array_agg(struct(org_name, id) order by fhoffa.x.levenshtein(org, org_name) limit 1)[offset(0)].*
from orgs, orgs_ids
group by org
if applied to sample data in your question - output is
CodePudding user response:
Maybe there is a way to run less accurate yet much more efficient match first to narrow down the number of combinations and then run more accurate matching?
Below is kind of doing this - a) splits all names b)soundex them c) gets winners based on count of matched words - you can adjust logic as you wish
select org, org_name, id
from (select * from orgs, unnest(split(org, ' ')) word) o
join (select * from orgs_ids, unnest(split(org_name, ' ')) word) i
on soundex(o.word) = soundex(i.word)
group by org, org_name, id
qualify 1 = row_number() over(partition by org order by count(1))
if applied to sample data in your question - output is