I'm a bit new to azure data factory so apologies if I'm missing anything obvious. I've done several searches and I can't find anything that quite fits.
So the situation is that we have an existing pipeline that will take the path to a csv file and pass this in as a delimited data set. As a sink it is using a parquet data set. This is a generic process that we can pass any delimited file into and it will output it as parquet.
This has been working well but now we have started receiving files with spaces and special characters in the header which causes the output to parquet to fail. Unfortunately we don't have control over the format of the files we receive so I can't handle this at source.
What I would like to do is on ingestion of the file replace any spaces and other special characters in the header with an underscore. If I were doing this on premise I could quickly create a powershell script to do it. I had thought about creating a custom task in AFD to call a powershell script to do this in the blob storage but that seems more complicated than it should be. Is there something else I can do to get this process working while keeping it generic?
CodePudding user response:
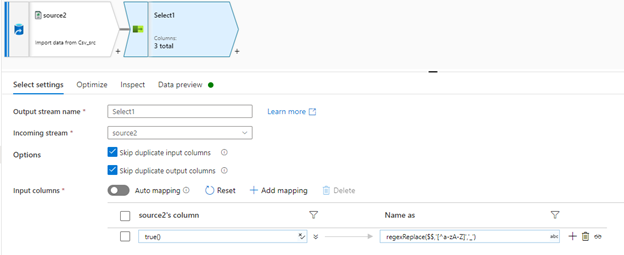
As @Joel Cochran mentioned, you can use the below expression in Select transformation to replace space and special characters in the header.
regexReplace($$,'[^a-zA-Z]','_')
Source:
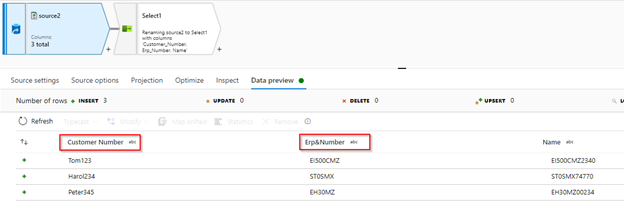
In Select transformation, remove the auto mappings and add new rule base mapping to use this expression.
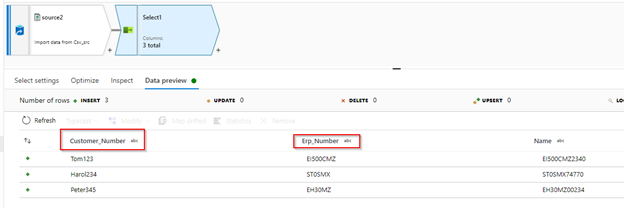
preview:
CodePudding user response:
You can change the output filename not directly in the Copy activity, assuming you are using this activity.
The workaround is to use a parameter for the filename output that you can cleanup.
- You can use the Get Metadata activity to get all filenames from the source csv files.
- Then loop over these files with a foreach activity.
- Within the foreach activity you can set the output filename with the new name with the cleaned value.
The function could look like this:
@replace(@item.name, ' ', '_')