I have a sample dataframe as given below.
import pandas as pd
import numpy as np
NaN = np.nan
data = {'ID':['A', 'A', 'A', 'B','B','B'],
'Date':['2021-09-20 04:34:57', '2021-09-20 04:37:25', '2021-09-20 04:38:26', '2021-09-01
00:12:29','2021-09-01 11:20:58','2021-09-02 09:20:58'],
'Name':['xx','xx',NaN,'yy',NaN,NaN],
'Height':[174,174,NaN,160,NaN,NaN],
'Weight':[74,NaN,NaN,58,NaN,NaN],
'Gender':[NaN,'Male',NaN,NaN,'Female',NaN],
'Interests':[NaN,NaN,'Hiking,Sports',NaN,NaN,'Singing']}
df1 = pd.DataFrame(data)
df1
I want to combine the data present on the same date into a single row. The 'Date' column is in timestamp format. I have written a code for it. Here is my TRY code:
TRY:
df1['Date'] = pd.to_datetime(df1['Date'])
df_out = (df1.groupby(['ID', pd.Grouper(key='Date', freq='D')])
.agg(lambda x: ''.join(x.dropna().astype(str)))
.reset_index()
).replace('', np.nan)
This gives an output where if there are multiple entries of same value, the final result has multiple entries in the same row as shown below.
Obtained Output
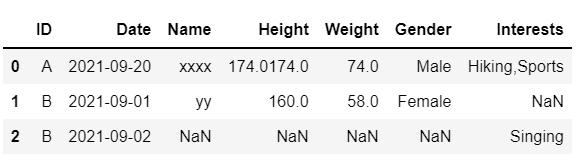 However, I do not want the values to be repeated if there are multiple entries. The final output should look like the image shown below.
However, I do not want the values to be repeated if there are multiple entries. The final output should look like the image shown below.
Required Output
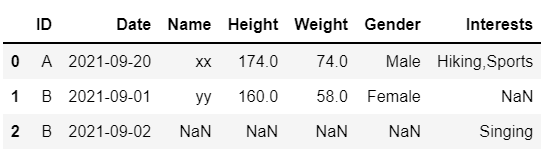
The first column should not have 'xx' and 174.0 instead of 'xxxx' and '174.0 174.0'.
Any help is greatly appreciated. Thank you.
CodePudding user response:
Since you're only trying to keep the first available value for each column for each date, you can do:
>>> df1.groupby(["ID", pd.Grouper(key='Date', freq='D')]).agg("first").reset_index()
ID Date Name Height Weight Gender Interests
0 A 2021-09-20 xx 174.0 74.0 Male Hiking,Sports
1 B 2021-09-01 yy 160.0 58.0 Female None
2 B 2021-09-02 None NaN NaN None Singing
CodePudding user response:
In your case replace agg join to first
df_out = (df1.groupby(['ID', pd.Grouper(key='Date', freq='D')])
.first()
.reset_index()
).replace('', np.nan)
df_out
Out[113]:
ID Date Name Height Weight Gender Interests
0 A 2021-09-20 xx 174.0 74.0 Male Hiking,Sports
1 B 2021-09-01 yy 160.0 58.0 Female None
2 B 2021-09-02 None NaN NaN None Singing