I have a large pipe-delimited text file that should have one 3-column record per line. Many of the records are split up by line breaks within a column.
I need to do a find/replace to get three, and only three, pipes per line/record.
Here's an example (I added the line breaks (\r\n) to demonstrate where they are and what needs to be replaced):
12-1234|The quick brown fox jumped over the lazy dog.|Every line should look similar to this one|\r\n
56-7890A|This record is split\r\n
\r\n
on to multiple lines|More text|\r\n
09-1234AS|\r\n
||\r\n
\r\n
56-1234|Some text|Some more text\r\n
|\r\n
76-5432ABC|A record will always start with two digits, a dash and four digits|There may or may not be up to three letters after the four digits|\r\n
The caveat is that I need to retain those mid-record line breaks for the target system. They need to be replaced with \.br\. So the final result of the above should look like this:
12-1234|The quick brown fox jumped over the lazy dog.|Every line should look similar to this one|\r\n
56-7890A|This record is split\.br\\.br\on multiple lines|More text|\r\n
09-1234AS|\.br\||\.br\\r\n
56-1234|Some text|Some more text\.br\|\r\n
76-5432ABC|A record will always start with two digits, a dash and four digits|There may or may not be up to three letters after the four digits|\r\n
As you can see the mid-record line breaks have all been replaced with \.br\ and the end-of-line line breaks have been retained to keep each three-column/pipe record on its own line. Note the last record's text, explaining how each line/record begins. I included that in case that would help in building a regex to properly identify the beginning of a record.
I'm not sure if this can be done in one find/replace step or if it needs to be (or just should be) split up into a couple of steps.
I had the thought to first search for |\r\n, since all records end with a pipe and a CRLF, and replace those with dummy text !@#$. Then search for the remaining line breaks with \r\n, which will be mid-column line breaks and replace those with \.br\, then replace the dummy text with the original line breaks that I want to keep |\r\n.
That worked for all but records that looked like the third record in the first example, which has several line breaks after a pipe within the record. In such a large file as I am working with it wasn't until much later that I found that the above process I was using didn't properly catch those instances.
CodePudding user response:
You can use
(?:\G(?!^(?<!.))|^\d{2}-\d [A-Z]*\|[^|]*?(?:\|[^|]*?)?)\K\R
Replace with \\.br\\. See the 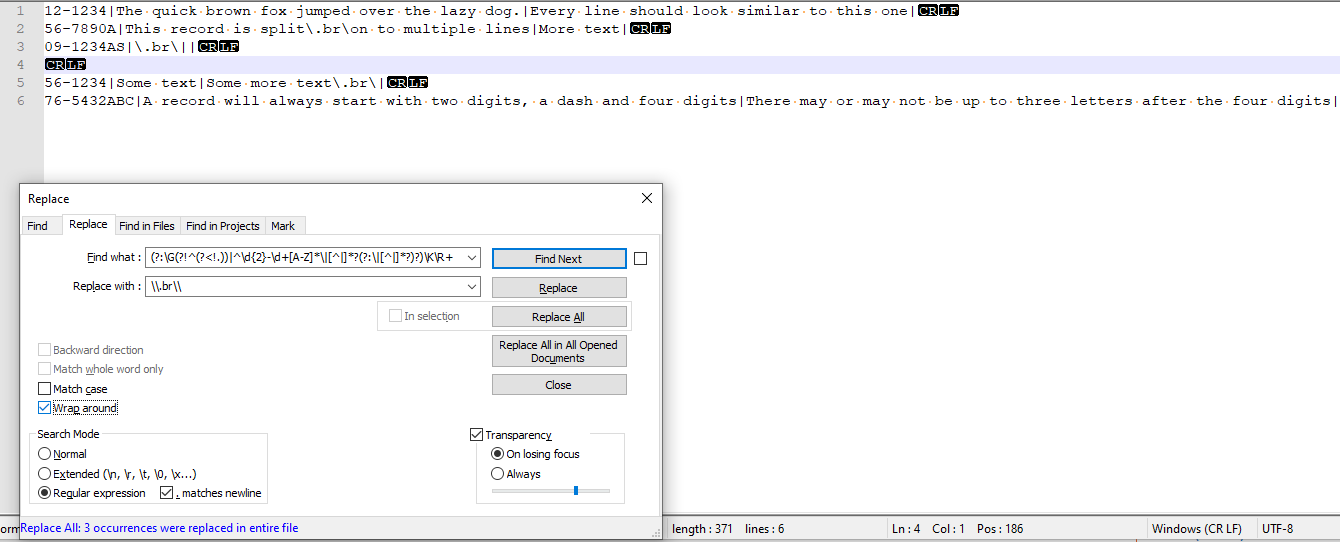
If you need to remove empty lines after this, use Edit > Line Operations > Remove Empty Lines.