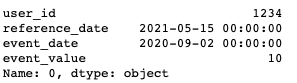
I have a dataframe with the following columns: user ID, reference date, date of event, event value.
- User IDs are unique, and there are multiple entries for each ID
- Reference date is unique to each user ID
I want to find the indices of the events that happen closest to the reference date, both before and after.
Example:
| user_id | reference_date | event_date | event_value |
|---|---|---|---|
| 1234 | 2021-05-15 | 2020-09-02 | 10 |
| 1234 | 2021-05-15 | 2021-04-28 | 15 |
| 1234 | 2021-05-15 | 2021-06-01 | 11 |
The code should return something like
| user_id | reference_date | event_1 | value_1 | event_2 | value_2 |
|---|---|---|---|---|---|
| 1234 | 2021-05-15 | 2021-04-28 | 15 | 2021-06-01 | 11 |
CodePudding user response:
You can easily do it using a merge_asof statement while setting the direction argument to the nearest, like this:
df_merged = pd.merge_asof(df1, df2, on=['user_id'], direction='nearest')
Just before that, ensure that your dates are in date format using:
df['reference_date'] = pd.to_datetime(df['reference_date'])
df['event_date'] = pd.to_datetime(df['event_date'])
So, to have it as a whole in the context, the code should look like this:
import pandas as pd
my_dict = {'user_id':[1234, 1234, 1234], \
'reference_date':['2021-05-15', '2021-05-15', '2021-05-15'], \
'event_date':['2020-09-02', '2021-04-28', '2021-06-01'], \
'event_value':[10, 15, 11]}
df = pd.DataFrame(my_dict)
df['reference_date'] = pd.to_datetime(df['reference_date'])
df['event_date'] = pd.to_datetime(df['event_date'])
df1 = df[['user_id','reference_date']]
df2 = df[['user_id','reference_date','event_date','event_value']]
df_merged = pd.merge_asof(df1, df2, on=['user_id'], direction='nearest')
df_merged = df_merged.drop_duplicates(subset=['user_id'])
print(df_merged)
CodePudding user response:
import pandas as pd
from io import StringIO
# Sample data but added an additonal group
s = """user_id,reference_date,event_date,event_value
1234,2021-05-15,2020-09-02,10
1234,2021-05-15,2021-04-28,15
1234,2021-05-15,2021-06-01,11
12346,2021-05-20,2021-09-02,10
12346,2021-05-20,2021-06-28,15
12346,2021-05-20,2021-06-01,11"""
df = pd.read_csv(StringIO(s))
# convert dates to datetime
df['reference_date'] = pd.to_datetime(df['reference_date'])
df['event_date'] = pd.to_datetime(df['event_date'])
# Filter your df using loc
# Calculate the difference between the reference and event date
# groupby and get the index of the min values using idxmin
df.loc[df.assign(diff=abs(df[['reference_date',
'event_date']].diff(axis=1)['event_date']))\
.groupby(['user_id', 'reference_date'])['diff'].idxmin()]
user_id reference_date event_date event_value
1 1234 2021-05-15 2021-04-28 15
5 12346 2021-05-20 2021-06-01 11
If you want to keep all the min values and not just the first occurrence then use groupby with transform
d = df.assign(diff=abs(df[['reference_date', 'event_date']].diff(axis=1)['event_date']))
df[d['diff'] == d.groupby(['user_id', 'reference_date'])['diff'].transform(min)]
user_id reference_date event_date event_value
1 1234 2021-05-15 2021-04-28 15
2 1234 2021-05-15 2021-06-01 11
5 12346 2021-05-20 2021-06-01 11
CodePudding user response:
def fcl(df, dtObj):
return df.iloc[np.argmin(np.abs(df.index.to_pydatetime() - dtObj))]
ArgMin finds the global minimum of f subject.
So this just returns an element, which has the minimum difference between 2 dates.
This function returns the closest date in df, where dtObj - is that date.
For use in your case:
def fcl(df, columnName, dtObj):
return df.iloc[np.argmin(np.abs(df[columnName] - dtObj))]
date = "2021-02-15"
date = pd.to_datetime(date)
test = fcl(df,'reference_date', date)
of course, the dtObject can be columnName argument or event_date - like here:
def fcl(df, columnName, dtObj):
return df.iloc[np.argmin(np.abs(df[columnName] - df['event_date']))]
output: