I have the following RDD
2019-09-24,Debt collection,transworld systems inc. is trying to collect a debt that is not mine not owed and is inaccurate.
2019-09-19,Credit reporting credit repair services or other personal consumer reports,
with each one of the 3 elements representing accordingly
- Date
- Label
- comments
I need to apply a filter transformation in order to keep only the records that start with '201' (for the date) and include comments (they have value and are not an empty string in the third element).
I am using the following code in order to calculate each time how many records have been reduced from the filtering transformations:
countA = rdd.count()
countB = rdd.filter(lambda x: x.startswith('201')).count()
countC = rdd.filter(lambda x: x.startswith('201') & (x.split(",")[2] != None) & (len(x.split(",")[2]) > 0)).count()
my code crashes in the calculation of countC and although it seems as the filtering works in my further calculations I get more errors as well...
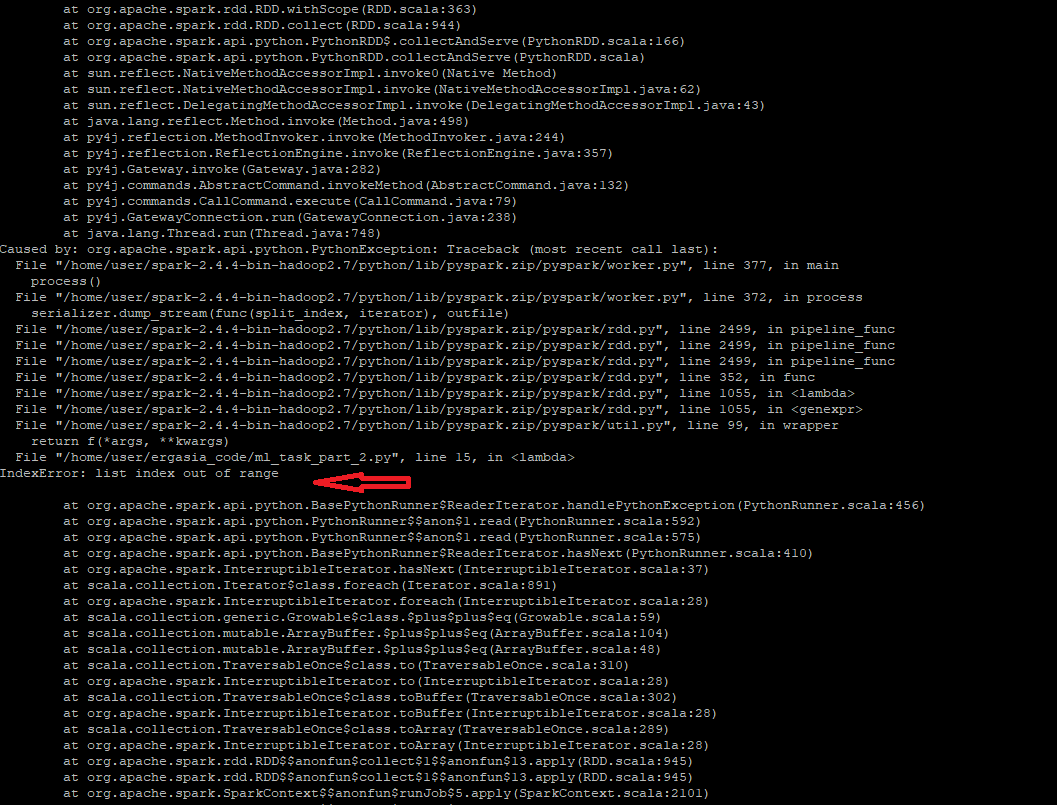
CodePudding user response:
You are getting the error :
IndexError: list index out of range
because you are trying to access the index 2 of a list (the result of your split) which may not exist if some rows in your dataset only have Date or Date and Label or are empty or may have formatting issues.
In your lambda function you may take advantage of short-circuiting in python to first check if there are at least 3 elements (i.e. an index of 2 is possible using len(x.split(",")) >=3 instead of (x.split(",")[2] != None)) before trying to access this index.
This may be written as:
countC = rdd.filter(lambda x: x.startswith('201') and (len(x.split(",")) >=3) and (len(x.split(",")[2]) > 0))
Let me know if this works for you.