I have a dataset like below:
campaign_name
abcloancde
abcsolcdf
abcemicdef
emic_estore
Personalloa-nemic_sol
personalloa_nemic
abc/emic-dg-upi:bol
where campaign_name is the column name. I have another dictionary like below:
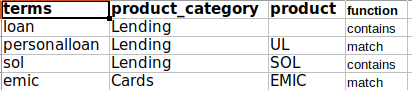
According to my use case, I have to sort the dictionary on the basis of the length of terms in descending order and have to map it with the campaign_name column. Whichever terms are FOUND FIRST in campaign_name, its associated product_category and product should be picked up. For this, I wrote the below code and it works fine:
#Dataset loaded below
initialData = spark.read.option("header", "true").csv("file://..../sample_data.csv")
initialData.show()
#Dictionary loaded below
df = spark.read.option("header",
"true").csv("file://..../mapper.csv")
df_contains = df.filter(df.function == 'contains').drop("function")
df_contains = df_contains.orderBy(length(col("terms")).desc())
w = Window.partitionBy(lit('A')).orderBy(length(col("terms")).desc())
df_contains = df_contains.withColumn("rw", row_number().over(w))
df3 = df_contains.na.fill("").groupBy(lit(1)).agg(collect_list(
concat(col("rw"), lit(":"), col("terms"), lit(":"), col("product_category"), lit(":"), col("product"))).alias(
"Check")).withColumn("Check", concat_ws(",", col("Check"))).drop("1")
def categoryFunction(name, Check):
# checkList = Check.lower().split(",")
out = ""
match = False
for Key in Check.lower().split(","):
keyword = Key.split(":", 2)
terms = keyword[1]
tempOut = keyword[2]
if terms in name.lower():
out = tempOut
match = True
if match:
break
return out
def categoryFunction1(name, Check):
# checkList = Check.lower().split(",")
out = ""
match = False
for Key in Check.lower().split(","):
keyword = Key.split(":", 2)
terms = keyword[1]
tempOut = keyword[2]
if terms == name.lower():
out = tempOut
match = True
if match:
break
return out
categoryUDF = udf(categoryFunction, StringType())
categoryUDF1 = udf(categoryFunction1, StringType())
df4 = initialData.crossJoin(df3)
finalDF = df4.withColumn("out", categoryUDF(col("campaign_name"), col("Check"))).drop("Check").withColumn("out", split(
col("out"), ":")).withColumn("product_category", col("out")[0]).withColumn("product", col("out")[1]).drop(
"out").withColumn("prod", when(col("product").isNull(), "other").otherwise(col("product"))).withColumn("prod_cat",
when(
col("product_category") == "",
"other").otherwise(
col("product_category"))).drop(
"product", "product_category")
It gives me the below correct output:
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|abcloancde | |lending |
|abcsolcdf |sol |lending |
|abcemicdef |other|other |
|emic_estore |other|other |
|personalloan-emic_sol| |lending |
|personalloan_emic | |lending |
|abc/emic-dg-upi:bol |other|other |
--------------------- ----- --------
Now, I want to only pick the campaign_names where prod and prod_cat values are other. After getting such campaign_names I have to split the campaign_names on the basis of "_" and again run the condition against the dictionary where function="match" and pick the product and product_category as done for contains
I have written a categoryFunction1 UDF for this and it actually works when I am filtering out the required dataset for the match condition and doing whatever I need to do and then doing union with the above output(which updates the values for "other").
Is there any way like by using "case...when..then" which explodes the data as I need and doing the crossJoin and then picking up the FIRST EXACT MATCH value? Because I am dealing with billions of records so wanted to think of a more optimal solution.
Final expected output(contains exact):
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|abcloancde | |lending |
|abcsolcdf |sol |lending |
|abcemicdef |other|other |
|emic_estore |emic |cards |
|personalloan-emic_sol| |lending |
|personalloan_emic | |lending |
|abc/emic-dg-upi:bol |other|other |
--------------------- ----- --------
Catch:
There is one scenario that I missed in the question. I have to eliminate all the delimiters while comparing for contains and for the exact match I can consider all the delimiters but just have to split the words on the basis of "_" and then compare them.
Any suggestions are much appreciated.
CodePudding user response:
UDFs can be expensive on a spark cluster when compared to using the spark api which can take advantage of spark optimizations. I understand why you created df3 to include in your udfs, however this may not be necessary. Especially when the size of your dictionary data may grow and the aggregations to create df3 can be expensive and result in data spills (from memory to disk) since you are grouping everything in 1 row. If it is considerably smaller than the campaign data you may opt to broadcast the dataframe with the dictionary data.
Based on your sample data df_contains has the following
df_contains = dictionaryDf.filter(dictionaryDf.function == 'contains').drop("function").na.fill("")
df_contains.show(truncate=False)
----- ---------------- -------
|terms|product_category|product|
----- ---------------- -------
|loan |Lending | |
|sol |Lending |SOL |
----- ---------------- -------
Another approach using only the spark api is to:
Approach 1
Part 1
NB. You've already achieved part 1 using your UDFs
- Left join the dictionary data (broadcast if this improves your performance) on whether the term is located in the campaign name.
- You may then use the window function row number to identify the longest term first or as you have described it :
I have to sort the dictionary on the basis of the length of terms in descending order and have to map it with the campaign_name column
- Select your desired columns and use your case expression logic (i.e. with when)
The approach may be coded as below:
from pyspark.sql import functions as F
output_df = (
# Step 1
initial_data.join(
F.broadcast(df_contains),
F.col("campaign_name").contains(F.col("terms")),
"left"
)
# Step 2
.withColumn(
"rn",
F.row_number().over(
Window.partitionBy("campaign_name")
.orderBy(
F.length(F.col("terms")).desc()
)
)
)
.filter("rn=1")
# Step 3
.select(
"campaign_name",
F.when(
F.col("product").isNull(),"other"
).otherwise(F.col("product")).alias("prod"),
F.when(
F.col("product_category").isNull(),"other"
).otherwise(F.col("product_category")).alias("prod_cat")
)
)
output_df.show(truncate=False)
which results in the following output (NB. ordering of rows in spark is non-deterministic unless an order is specified) :
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|abc/emic-dg-upi:bol |other|other |
|abcemicdef |other|other |
|abcloancde | |Lending |
|abcsolcdf |SOL |Lending |
|emic_estore |other|other |
|personalloan-emic_sol| |Lending |
|personalloan_emic | |Lending |
--------------------- ----- --------
Part 2
We may solve the remainder of your problem with a similar approach as above
- Split the
campaign_nameby_and useexplodeto get multiple rows for each piece - Left Join on the split campaign name, aliased below as
cname_split, and whereprodandprod_catare equal tootherfor the split campaign names - Instead of using a when/case expression to check for null matches and re-assign the original value we may use
coalescewhich assigns the first non-null value - Since we have multiple rows for each
campaign_nameafter the explode, we may aggregate, however in the example below, I've usedrow_numberto filter the duplicate entries and order by availableproductnames.
NB. df_match as referenced below was retrieved using
df_match = dictionaryDf.filter(dictionaryDf.function == 'match').drop("function").na.fill("")
df_match.show(truncate=False)
------------ ---------------- -------
|terms |product_category|product|
------------ ---------------- -------
|personalloan|Lending |UL |
|emic |Cards |EMIC |
------------ ---------------- -------
Code:
from pyspark.sql import functions as F
output_df2 = (
# Step 1
output_df.select(
"*",
F.explode(F.split("campaign_name","_")).alias("cname_split")
)
# Step 2
.join(
df_match,
(
F.col("campaign_name").contains("_") &
F.col("cname_split").contains(F.col("terms")) &
(F.col("prod") == "other") &
(F.col("prod_cat") == "other")
),
"left"
)
# Step 3
.select(
"campaign_name",
F.coalesce("product","prod").alias("prod"),
F.coalesce("product_category","prod_cat").alias("prod_cat"),
# Step 4
F.row_number().over(
Window.partitionBy("campaign_name")
.orderBy(
F.col("product").isNull()
)
).alias("rn")
)
.filter("rn=1")
.drop("rn")
)
output_df2.show(truncate=False)
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|abc/emic-dg-upi:bol |other|other |
|abcemicdef |other|other |
|abcloancde | |Lending |
|abcsolcdf |SOL |Lending |
|emic_estore |EMIC |Cards |
|personalloan-emic_sol| |Lending |
|personalloan_emic | |Lending |
--------------------- ----- --------
Approach 2
This is similar to the approach above however, it is more optimal as it achieves it's aim using less joins.
Code:
from pyspark.sql import functions as F
output_df3 = (
initial_data.withColumn("cname_split",F.explode(F.split("campaign_name","_")))
.join(
dictionaryDf,
(
(
(F.col("function")=="contains") &
F.col("campaign_name").contains(F.col("terms"))
) |
(
(F.col("function")=="match") &
F.col("campaign_name").contains("_") &
F.col("cname_split").contains(F.col("terms"))
)
),
"left"
)
.withColumn(
"empty_is_other",
F.when(
(
F.col("product").isNull() &
F.col("product_category").isNull()
),
"other"
)
)
.withColumn(
"rn",
F.row_number().over(
Window.partitionBy("campaign_name")
.orderBy(
F.when(
F.col("function").isNull(),3
).when(
F.col("function")=="match",2
).otherwise(1),
F.length(F.col("terms")).desc(),
F.col("product").isNull()
)
)
)
.filter("rn=1")
.select(
"campaign_name",
F.coalesce("product","empty_is_other").alias("prod"),
F.coalesce("product_category","empty_is_other").alias("prod_cat"),
)
.na.fill("")
)
output_df3.show(truncate=False)
Outputs
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|abc/emic-dg-upi:bol |other|other |
|abcemicdef |other|other |
|abcloancde | |Lending |
|abcsolcdf |SOL |Lending |
|emic_estore |EMIC |Cards |
|personalloan-emic_sol| |Lending |
|personalloan_emic | |Lending |
--------------------- ----- --------
Output before .filter("rn=1") for clarification
--------------------- ------------------- ------------ ---------------- ------- -------- -------------- ---
|campaign_name |cname_split |terms |product_category|product|function|empty_is_other|rn |
--------------------- ------------------- ------------ ---------------- ------- -------- -------------- ---
|abc/emic-dg-upi:bol |abc/emic-dg-upi:bol|null |null |null |null |other |1 |
|abcemicdef |abcemicdef |null |null |null |null |other |1 |
|abcloancde |abcloancde |loan |Lending |null |contains|null |1 |
|abcsolcdf |abcsolcdf |sol |Lending |SOL |contains|null |1 |
|emic_estore |emic |emic |Cards |EMIC |match |null |1 |
|emic_estore |estore |null |null |null |null |other |2 |
|personalloan-emic_sol|personalloan-emic |loan |Lending |null |contains|null |1 |
|personalloan-emic_sol|sol |loan |Lending |null |contains|null |2 |
|personalloan-emic_sol|personalloan-emic |sol |Lending |SOL |contains|null |3 |
|personalloan-emic_sol|sol |sol |Lending |SOL |contains|null |4 |
|personalloan-emic_sol|personalloan-emic |personalloan|Lending |UL |match |null |5 |
|personalloan-emic_sol|personalloan-emic |emic |Cards |EMIC |match |null |6 |
|personalloan_emic |personalloan |loan |Lending |null |contains|null |1 |
|personalloan_emic |emic |loan |Lending |null |contains|null |2 |
|personalloan_emic |personalloan |personalloan|Lending |UL |match |null |3 |
|personalloan_emic |emic |emic |Cards |EMIC |match |null |4 |
--------------------- ------------------- ------------ ---------------- ------- -------- -------------- ---
Update 1
In response to question update:
Catch:
There is one scenario that I missed in the question. I have to eliminate all the delimiters while comparing for contains and for the exact match I can consider all the delimiters but just have to split the words on the basis of "_" and then compare them.
regexp_replace was used to remove special characters. See update below:
output_df3 = ( # _/:
initial_data.withColumn("cname_split",F.explode(F.split("campaign_name","_")))
.withColumn(
"campaign_name_clean",
F.regexp_replace(
F.lower(F.col("campaign_name")),
'[^a-zA-Z0-9]',
""
)
)
.join(
dictionaryDf,
(
(
(F.col("function")=="contains") &
F.col("campaign_name_clean").contains(F.col("terms"))
) |
(
(F.col("function")=="match") &
F.col("campaign_name").contains("_") &
(F.col("cname_split")==F.col("terms"))
)
),
"left"
)
.withColumn(
"empty_is_other",
F.when(
(
(
(F.col("function")=="contains") | F.col("function").isNull()
) &
F.col("product").isNull() &
F.col("product_category").isNull()
),
"other"
)
)
.withColumn(
"rn",
F.row_number().over(
Window.partitionBy("campaign_name")
.orderBy(
F.when(
F.col("function").isNull(),3
).when(
F.col("function")=="match",2
).otherwise(1),
F.length(F.col("terms")).desc(),
F.col("product").isNull()
)
)
)
.filter("rn=1")
.select(
"campaign_name",
F.coalesce("product","empty_is_other").alias("prod"),
F.coalesce("product_category","empty_is_other").alias("prod_cat"),
)
.na.fill("")
)
output_df3.show(truncate=False)
Outputs:
--------------------- ----- --------
|campaign_name |prod |prod_cat|
--------------------- ----- --------
|Personalloa-nemic_sol| |Lending |
|abc/emic-dg-upi:bol |other|other |
|abcemicdef |other|other |
|abcloancde | |Lending |
|abcsolcdf |SOL |Lending |
|emic_estore |EMIC |Cards |
|personalloa_nemic | |Lending |
--------------------- ----- --------
Output before .filter("rn=1") for debugging purposes
--------------------- ------------------- ------------------- ----- ---------------- ------- -------- -------------- ---
|campaign_name |cname_split |campaign_name_clean|terms|product_category|product|function|empty_is_other|rn |
--------------------- ------------------- ------------------- ----- ---------------- ------- -------- -------------- ---
|Personalloa-nemic_sol|Personalloa-nemic |personalloanemicsol|loan |Lending |null |contains|null |1 |
|Personalloa-nemic_sol|sol |personalloanemicsol|loan |Lending |null |contains|null |2 |
|Personalloa-nemic_sol|Personalloa-nemic |personalloanemicsol|sol |Lending |SOL |contains|null |3 |
|Personalloa-nemic_sol|sol |personalloanemicsol|sol |Lending |SOL |contains|null |4 |
|abc/emic-dg-upi:bol |abc/emic-dg-upi:bol|abcemicdgupibol |null |null |null |null |other |1 |
|abcemicdef |abcemicdef |abcemicdef |null |null |null |null |other |1 |
|abcloancde |abcloancde |abcloancde |loan |Lending |null |contains|null |1 |
|abcsolcdf |abcsolcdf |abcsolcdf |sol |Lending |SOL |contains|null |1 |
|emic_estore |emic |emicestore |emic |Cards |EMIC |match |null |1 |
|emic_estore |estore |emicestore |null |null |null |null |other |2 |
|personalloa_nemic |personalloa |personalloanemic |loan |Lending |null |contains|null |1 |
|personalloa_nemic |nemic |personalloanemic |loan |Lending |null |contains|null |2 |
--------------------- ------------------- ------------------- ----- ---------------- ------- -------- -------------- ---
Let me know if this works for you.