I am writing a small program that reads from a text file that contains many items as the ones that we buy at a grocery store. This program is part of a larger application in which I am integrating Python and C , but for simplicity, I isolated this part of the app since it seems to be where the problem is.
The problem is that the first item in the text file (Spinach) exists 5 times in the txt file but the program prints some garbage data, then Spinach and then 1 as the number that represents the many times the word Spinach exists in the file. But it should be 5. Down the list of items you can also see that the word Spinach is printed again but this time with the number 4 representing the number of times it exists in the txt file. But the word Spinach should print only once along with number 5 representing the times it exists in the txt file. Example, Spinash - 5. View image below.
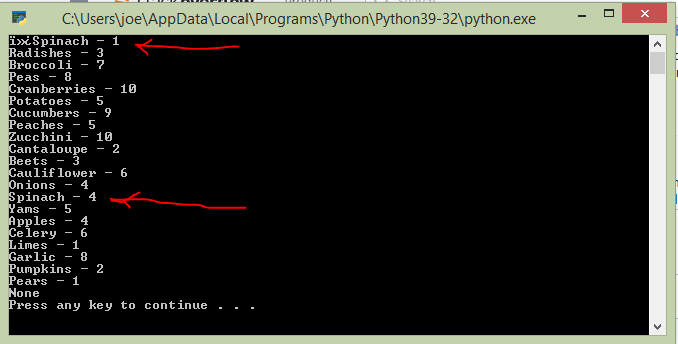 ,
,
I am not sure if the problem is in the freq = {} dictionary. Please, could someone help me to figure out what is causing the issue? Please, be specific since I am just now learning python. Please, view the code below for the .py file and also view the list of items in the .txt file.
Thank you in advance for your help.
App.py
def wordFrequency(item): # This function gets called printed out by WordFrequency , it takes one argument which passes from cpp
count = 0 # this variable is use to count the frequency of the list iitem
with open('items.txt')as myfile: # opening file
lines = myfile.readlines() #reading all the lines of the file
for line in lines:
if(line.strip("\n") == item): # removing the \n from the last
count 1
myfile.close()
return count
# Display only
def displayWordFrequency():
with open('items.txt')as myfile: # opening file
lines = myfile.readlines()
freq ={} # using dictionary to store the value of the list
for line in lines:
if(line.strip("\n") in freq): # put the condition if the value is present aleady then it will increment it otherwise it will put one for it
freq[line.strip("\n")] = 1 #strip to remove \n which passes as an argument
else:
freq[line.strip("\n")] = 1
for key , value in freq.items(): # loops through dictionary and prints the values
print(f"{key} - {value}") # Key is the string and the value is the integer
myfile.close()
print(displayWordFrequency())
items.txt
Spinach
Radishes
Broccoli
Peas
Cranberries
Broccoli
Potatoes
Cucumbers
Radishes
Cranberries
Peaches
Zucchini
Potatoes
Cranberries
Cantaloupe
Beets
Cauliflower
Cranberries
Peas
Zucchini
Peas
Onions
Potatoes
Cauliflower
Spinach
Radishes
Onions
Zucchini
Cranberries
Peaches
Yams
Zucchini
Apples
Cucumbers
Broccoli
Cranberries
Beets
Peas
Cauliflower
Potatoes
Cauliflower
Celery
Cranberries
Limes
Cranberries
Broccoli
Spinach
Broccoli
Garlic
Cauliflower
Pumpkins
Celery
Peas
Potatoes
Yams
Zucchini
Cranberries
Cantaloupe
Zucchini
Pumpkins
Cauliflower
Yams
Pears
Peaches
Apples
Zucchini
Cranberries
Zucchini
Garlic
Broccoli
Garlic
Onions
Spinach
Cucumbers
Cucumbers
Garlic
Spinach
Peaches
Cucumbers
Broccoli
Zucchini
Peas
Celery
Cucumbers
Celery
Yams
Garlic
Cucumbers
Peas
Beets
Yams
Peas
Apples
Peaches
Garlic
Celery
Garlic
Cucumbers
Garlic
Apples
Celery
Zucchini
Cucumbers
Onions
CodePudding user response:
You can achieve that using a dictionary comprehnsion looping over the the set of the data to remove duplicates. To keep the order you have to look back to the original list
# see question for full list
s = """Spinach
Radishes
Broccoli
Peas
Cranberries
Broccoli
Potatoes
Cucumbers
...
Celery
Zucchini
Cucumbers
Onions"""
s = s.split('\n') # get the data as list
s_dict = {k: s.count(k) for k in set(s)}
original_indices = sorted(map(s.index, set(s)))
print('\n'.join(' - '.join((s[i], str(s_dict[s[i]]))) for i in original_indices))
EDIT
If you are using dictionaries and the order is important it would be better to use the implementation from the standard library 
CodePudding user response:
The general principle outlined by @Fredericka can be implemented like this:
mydict = dict()
with open('items.txt') as items:
for key in [s.strip() for s in items.readlines()]:
mydict.setdefault(key, [0])[0] = 1
for k, v in mydict.items():
print(f'{k} - {v[0]}')