I created a decision tree in R using the "tree" package, however, then I look at the details of the model, I struggle with interpreting the results. The output of the model looks like this:
> model
node), split, n, deviance, yval
* denotes terminal node
1) root 23 16270.0 32.350
2) Y1 < 31 8 4345.0 59.880 *
3) Y1 > 31 15 2625.0 17.670
6) Y2 < 11.5 8 1310.0 26.000 *
7) Y2 > 11.5 7 124.9 8.143 *
I don't understand the numbers that are shown in each line after the features. what are 16270.0 and 32.350? Or what are 2625.0 and 17.670? Why do some of the numbers have asterisks? Any help is appreciated.
Thank you
CodePudding user response:
The rules that you got are equivalent to the following tree.
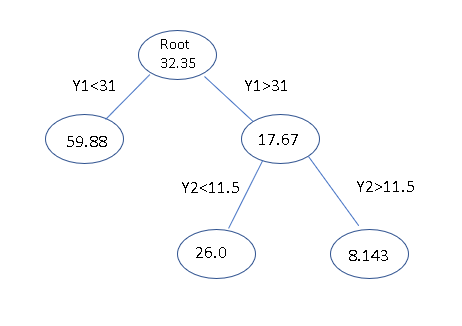
Each row in the output has five columns. Let's look at one that you asked about:
Y1 > 31 15 2625.0 17.670
Y1 > 31 is the splitting rule being applied to the parent node
15 is the number of points that would be at this node of the tree
2625.0 is the deviance at this node (used to decide how the split was made)
17.670 is what you would predict for points at this node
if you split no further.
The asterisks indicate leaf nodes - ones that are not split any further.
So in the node described above, Y1 > 31, You could stop at that node and
predict 17.670 for all 15 points, but the full tree would split this into
two nodes: one with 8 points for Y2 < 11.5 and another with 7 points for
Y2 > 11.5. If you make this further split, you would predict 26.0 for the 8 points
with Y2 < 11.5 (and Y1 > 31) and predict 8.143 for the 7 points with Y2 > 11.5
(and Y1 > 31).