I have a merged dataframe that looks like this.
import requests
import pandas as pd
from pandas import DataFrame
from matplotlib import pyplot as plt
import seaborn as sns
# Intitialise data of lists
data = [{'LocationA': '1001', 'YearA':'2013', 'Revenue':'55000', 'LocationB':'1001', 'YearB': '2013', 'Type':'Capital', 'Expense':'4000'},
{'LocationA': '1001', 'YearA':'2014', 'Revenue':'195000', 'LocationB':'1001', 'YearB': '2014', 'Type':'Capital', 'Expense':'40000'},
{'LocationA': '1001', 'YearA':'2015', 'Revenue':'10000', 'LocationB':'1001', 'YearB': '2015', 'Type':'Capital', 'Expense':'1000'},
{'LocationA': '1001', 'YearA':'2015', 'Revenue':'10000', 'LocationB':'1001', 'YearB': '2015', 'Type':'Operating', 'Expense':'5000'},
{'LocationA': '1001', 'YearA':'2016', 'Revenue':'25000', 'LocationB':'1001', 'YearB': '2016', 'Type':'Operating', 'Expense':'10000'}]
df = pd.DataFrame(data)
df
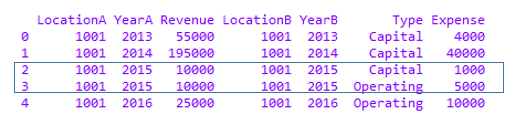
I tried to do the merge using inner, left, right, and outer. In all scenarios, I get Revenue = 10000 repeating 2x and, I guess, this happens because I have a Capital of 1000 and Operating of 5000.
My question is this...
How can I do a count of matches in multiple columns and divide by the count? In this scenario, LocationA is duped, YearA AND Revenue AND LocationB AND YearB, are dupes. These, combined, are counted 2x. I'd like to derive this 2, somehow, and divide Revenue by 2. How can I do that? Or, is the whole concept flawed?
CodePudding user response:
You can apply a custom function to get your desired result:
print (df.assign(Revenue=df["Revenue"].astype(int))
.groupby(["LocationA", "YearA", "LocationB", "YearB"])["Revenue"]
.apply(lambda d: d.mean()/d.count()))
LocationA YearA LocationB YearB
1001 2013 1001 2013 55000.0
2014 1001 2014 195000.0
2015 1001 2015 5000.0
2016 1001 2016 25000.0
Name: Revenue, dtype: float64
Note that mean was used but you can also use the first value like d.iat[0]/d.count() instead.